REST Workshop:Rust 计算化学程序开发
该仓库以 RHF 与 RCCSD(T) 为例子,用于演示 Rust 语言下,计算化学程序的快速开发与高性能实现的一种策略与工程实践。
该仓库将使用 RSTSR (REST 子项目) 作为数学库工具,libcint (Rust binding and wrapper) 作为电子积分引擎。我们将展示 RSTSR 在单一语言框架 (Rust) 下,可以同时兼顾开发效率与运行效率。
编译与测试
cargo build
cargo test --lib -- playground_ri_ccsdt --exact --nocapture
该项目由于开发过程也需要关注效率,因此在 debug 下仍然开启了 opt-level=2 优化选项。上述编译后的程序效率与 release 没有明显差异。
上述程序测试的是水分子 def2-TZVP 基组下的 RI-RCCSD(T) 能量计算。
该编译流程会从 github 上下载电子积分库 libcint 并作静态链接 (static linking)。如果 github 下载较慢,可以先下载好 libcint 的源码,并声明到环境变量 CINT_SRC。
前言
计算化学程序开发,与其他科学计算领域类似,有快速验证与高效实现的需求。
基于 REST 平台,我们在 Rust 语言下开发了 RSTSR 数学库工具,提供便利的程序接口,应对计算化学常见高维度张量的高效运算。
作为例子,我们快速高效地实现了 RHF 到 RCCSD(T) 一系列方法,展示 Rust 语言下计算化学程序 (或类似的科学计算任务) 开发的可能性。
目录
1. Rust 语言与计算化学
这里的核心问题是,为何 Rust 是适用于计算化学程序开发的语言?
1.1 程序开发的两个需求:快速验证与高效实现
计算化学程序用户比较关心程序功能是否全面、运行能力是否强大、程序是否易于使用。其中,运行能力是指是否可以高效地模拟较大的体系;这要求了程序性能必须足够高。
计算化学程序开发者还同时面临一些额外的问题:计算化学方法,特别是涉及到后自洽场、响应性质、激发态等问题的公式经常比较复杂。如何快速验证程序的正确性、并进一步作性能改善,是程序开发者面临的困难。
如何以客观的标准,评估程序语言或框架,是否能满足计算化学所需要的快速验证与高效实现?我们认为,
- 快速验证:因程序开发者经验与习惯差异而有不同看法;我们以代码行数作为客观标准,认为较短的代码比较契合快速开发的需求。理想情况下,一行公式能对应一行代码。
- 高效实现:在算法清晰、浮点数计算量 (FLOPs) 可以大致算出的前提下,我们可以对比计算设备的理论浮点计算能力 (FLOP/sec) 与程序的实际浮点计算效率,确认实现是否确实高效。
随着硬件与计算机语言的发展,早年时代表现好的程序,或许会在未来失去竞争力。但是,上面两个标准本身,不随计算机语言、硬件水平而不同;任何时代下的程序与框架应都可以此标准衡量。
1.2 Rust 语言:作为计算化学程序开发者的特色与不足
作为计算化学程序开发者,Rust 语言吸引我们的特色包括
- 与 C 同等级的性能;只要算法实现得当,几乎不存在因 Rust 语言本身的不足引起的性能问题;
- 现代函数式语言的表达能力、基于 trait 的泛型能力、强类型等适合于大型项目的语言特性;
- 内存安全性与无畏并行,能保证程序编写者调用失误的可能性大大下降;
- (除科学计算之外的) 程序生态丰富,在硬件层与底层应用上有诸多出色的项目。
Rust 语言的不足包括
- 作为编译语言,尽管支持增量编译,但其编译或链接时间仍然较长 (与 C++ 项目同等级,涉及到模板特化的耗时较多);
- REPL 支持有限,难以像 Python, Matlab, Mathematica, Julia 脚本式地运行程序1;
- 科学计算与 AI 生态与 GPU 支持还有待发展2。
Rust 语言具有争议的地方包括
- Rust 完全否定面向对象;必须通过类似于 C#、Java 的接口 (trait) 实现多态 (polymorphism);
- 语法上对重载 (overload) 的支持有限3。
Rust 语言与其他语言的对比:
- C++ 的表达能力非常自由,但程序编写者更容易写出错误的代码;C++ 语言本身复杂,编写程序时需要考虑引用、右值引用、移动等语义。
- Python 语言尽管可以写出效率很高的程序,但需要与其他语言 (C, C++, Rust) 或特殊的 Python 方言 (如 Numba) 结合才能达到高效率。Python 语言的类型检查较弱,非常便于快速验证、但不便于大型程序开发。
- Julia 语言尽管是少有的同时实现 REPL 与编译功能的语言,但其在科学计算之外的程序生态薄弱、有影响力的项目较少。
- Mojo, Moonbit 等语言吸收了 Python 与 Rust 等语言的特性,但目前仍在发展,现阶段不适合作为主力语言。
在语言上容易产生误解的地方包括
作为编译语言,Rust 必须要用很多代码实现脚本语言同样的功能:这个项目会表明,在合适的数学库框架下,Rust 语言可以用不太长的代码实现计算化学关心的问题。Python 下能用 行代码实现计算化学的算法,Rust 经常有办法在 行以内实现;Python 下不能高效实现的算法,Rust 可以实现。Rust 语言学习曲线陡峭:C++ 语言的学习难度未必低于 Rust,但这个问题因人而异。不考虑工程与架构,计算化学的算法实现所遇到的问题,大多不涉及 Rust 语法中困难的部分。尽管我们需要了解和使用 Rust 的生命周期,但我们的工作中不涉及循环链表和复杂的异步,因此并不需要对生命周期的所有细节都有所掌握。
2. 数学库 RSTSR
2.1 RSTSR 简介
该项目使用到数学库 RSTSR。
RSTSR 是 Rust 语言下,可用于处理张量存储与索引、以及对矩阵作线性代数运算的库。
- 功能与 API 对标 NumPy 与 SciPy,可以原生地在 Rust 语言下开发科学计算程序。对于习惯 NumPy 的用户,可以参考 NumPy-RSTSR 对照表 以快速熟悉 RSTSR 的使用。
- 支持多后端。目前 RSTSR 支持 OpenBLAS 与 Faer (纯 Rust 的数值代数库) 后端。未来会引入 MKL 与 CUDA 等其他后端。
- 涉及到矩阵线性代数的部分,性能由后端决定;其余的部分尽可能充分利用张量连续性与并行,性能较高。
- 同时支持行优先与列优先。
2.2 所有权问题
RSTSR 在使用上与 NumPy 有很多相似之处,但有一个非常大的区别在于数据所有权。
Rust 有非常严格的所有权规则;除非您的数据类型是 RC (reference counting) 智能指针,否则必须要区分数据是占有的还是引用的、对于引用类型还需要指定其生命周期。
RSTSR 的所有权规则参考自 Rust 库 ndarray;其简要说明可以参考 用户文档。调用的函数的过程中,
- 如果是不改变张量数据的操作 (比如索引、转置等),函数签名中没有
into_前缀的将返回引用类型张量视窗 (如函数i,transpose,swapaxes);若有into_前缀的则返回self自身的类型 (如函数into_reverse_axes)。 - 张量维度更改 (reshape) 是可能产生新数据的操作。
reshape将返回占有或视窗的张量 (copy-on-write 类型);into_shape将返回占有数据的张量。调用reshape或into_shape时,如果原先的张量数据足够连续,可以避免数据的复制,从而以近乎为零的开销实现维度更改。
3. 约定俗成
3.1 记号
- 本项目统一使用行优先 (row-major)。
- 本项目仅考虑闭壳层基态,不引入赝势 (ECP)。占据轨道数严格等于实际体系电子数的一半。
- 本项目仅考虑实函数。
指标规则为
| 意义 | 英文名称 | 公式指标 | 数量 | 数量程序变量 | 程序变量代号 |
|---|---|---|---|---|---|
| 占据轨道 | occupied | nocc | o | ||
| 非占轨道 | virtual | nvir | v | ||
| 所有分子轨道 | orbital | nmo | |||
| (原子轨道) 基组 | basis | nao | b | ||
| (原子轨道) 辅助基组 | auxiliary | naux | x | ||
| 原子核 | atom | natm |
3.2 张量与后端类型
本工作中,为了方便起见,后端类型声明为 DeviceTsr。若用户可以通过 cargo feature 指定 Faer 后端或 OpenBLAS 后端。
#![allow(unused)] fn main() { // prelude.rs #[cfg(not(feature = "use_openblas"))] pub type DeviceTsr = DeviceFaer; #[cfg(feature = "use_openblas")] pub type DeviceTsr = DeviceOpenBLAS; }
我们总是在 64 位浮点数、固定后端下进行开发;为了简化代码,张量类型则分别定义为
- 占有张量
Tsr - 不可变张量视窗
TsrView - 可变张量视窗
TsrMut
我们会在非常少数的情景下,使用固定维度张量 (相对于动态维度而言),因此保留维度泛型参数。
#![allow(unused)] fn main() { // prelude.rs pub type Tsr<D = IxD> = Tensor<f64, DeviceTsr, D>; pub type TsrView<'a, D = IxD> = TensorView<'a, f64, DeviceTsr, D>; pub type TsrMut<'a, D = IxD> = TensorMut<'a, f64, DeviceTsr, D>; }
4. 必要的性能分析背景
4.1 简单矩阵代数的 FLOPs 分析
在本项目中,我们会对 FLOPs 作简单分析。
-
对于矩阵乘法 (,,,其中 代表数据的类型)
则该计算的 FLOPs 总量是 ;其中的 系数来源与一次加法与一次乘法。
-
对于矩阵乘法
则该计算的 FLOPs 近似为 (由于 ,因此只需要作一半矩阵乘法,剩下一半通过转置得到)。
-
对于上三角或下三角矩阵 以及长方形矩阵 ,作下述三角矩阵乘法或求解
则该计算的 FLOPs 近似为 。
在以矩阵乘法为性能瓶颈的问题中,其他 FLOPs 通常是可以作为小量忽略的。但也要留意,除了矩阵乘法外,
- 在理想的程序实现、以及特定的算法下,内存带宽也会占用计算资源;
- 不理想的程序实现,会导致各种性能损耗,包括但不限于多余的内存资源分配与复制、低效率的指针索引、并行问题等等。
4.2 计算设备的理想性能
本文档着重于 CPU。CPU 厂商通常不会直接将 64 位浮点数矩阵乘法峰值能力标在产品说明上,我们通常需要自己作一些简单的换算。GPU 也可以作类似的分析,不过其峰值性能通常标注于产品说明,性能的比较会更加直观。
对于矩阵乘法问题,CPU 计算设备的理想性能是
- 物理内核数 (关闭超线程下的最大有效线程数);
- 乘加融合系数,固定为 2;
- 单个指令允许最大的数据大小 (对于 64 位浮点,x86 AVX-512 为 8、AVX2 为 4,ARM Neon 为 2);
- 为 FMA 指令通道数 (AMD Zen AVX-512 为 1、AVX2 为 2,Intel Xeon 与 ARM Neon 通常为 2);
- 为满负荷运行时,以 GHz 为单位的 CPU 频率。
本项目主要在个人电脑 AMD 7945HX 上测试。该设备的理想性能是 1.1 TFLOP/sec 或 1100 GFLOP/sec。
5. 前言结语
这份文档希望讨论程序的具体细节,以追求比较理想的程序性能。Rust 语言不仅能帮助我们较容易地达到理想性能,而且其具有较高的开发效率的潜力,适合计算化学的程序开发。
但也要留意,程序性能的提升经常只是改进;它当然也很重要,但真正的突破还需要依靠计算化学的算法、方法、或认知论的发展。
-
Rust 实际上有 REPL 库 evcxr,可以使用但体验与 Python 还是有差距的。作为参考,C++ xeus-cling 是类似的情况。 ↩
-
一方面除了 C/C++ 外,其他所有计算机语言对 GPU 的支持事实上都不足 (Fortran 有支持但较有限),大多都需要通过 FFI (foreign function interface) 实现。另一方面,只从 CUDA 生态而言,涉及 GPU 的代码应看作 CUDA 语言而非传统的 C/C++ (不是相同的语言);只是大多数工具链 (toolchain) 允许 CUDA 与 C/C++ 混合编译,使用上与语法上非常接近。从工程量上来看,使用 C/C++ 不一定就比使用其他语言更少。 ↩
-
一种常见的误解是 Rust 不能重载。实际上 Rust 具有重载能力 (基于 trait),RSTSR 也大量使用了 Rust 重载;它或许可以看作支持泛型的 C11
_Generic,与 Python 的 named-arguments 不同。但重载在 Rust 语言中的支持确实不足,导致现在很多 RSTSR 函数的参数必须打两个括号才能使用。 ↩
RHF:极简演示
- 程序:
rhf_slow.rs(gitee, github) - 实现内容:RHF (restricted Hartree-Fock, conventional 4c-2e)
- 不关注程序效率
- 该程序总共约 50 行
目录
1. RHF 回顾
RHF 方法是分子体系计算化学中最基础的方法。在 Bohn-Oppenheimer 近似下,假定原子核不运动,则分子体系的能量 可以视为原子核互斥能 与电子能量 之和:
其中,原子核互斥能量决定于原子核的相对位置 与其电荷数 :
Hartree-Fock 近似要求电子的波函数是 Slater 行列式。在闭壳层下 ( 自旋与 自旋的分子轨道与能级,在空间上对应相等),其最终表达式可以写为1
其中,
- 是 core Hamiltonian,它包含了动能 与电子-原子核势 。
- 是。
- 是电子云密度矩阵,它是由占据轨道系数 构成;其表达式中的 是指闭壳层下 轨道有两份贡献。
以上的量中, 是随体系确定的, 是待求解的。记号 代表我们将电子能量 视作关于密度矩阵 的函数。
RHF 要求密度矩阵 对应的占据轨道系数 满足正交归一条件
以此正交归一条件为前提,电子能量 取条件极小,即为体系的基态电子能量。上式中,重叠矩阵 是
定义能量对密度矩阵的导数矩阵 (该矩阵也称为 Fock 矩阵)
引入 Lagrangian 乘子 (由 Koopmans 的诠释, 一定条件下具有轨道能的物理意义),对能量作关于轨道系数 的条件极小,得到 Hartree-Fock-Roothaan 方程:
该问题恰好与第一类广义本征值问题等价2。当作为广义本征值问题时,求解得到的系数矩阵是 即基组平方大小的;在计算密度矩阵 时,需要取本征值最低的 个系数,重新构成 的 大小的矩阵。
2. 程序
2.1 输入与输出
整个程序中,涉及到的函数包括
#![allow(unused)] fn main() { pub fn get_energy_nuc(cint_data: &CInt) -> f64; pub fn minimal_rhf(cint_data: &CInt) -> RHFResults }
其中,输入参数 cint_data: &CInt 是定义了分子坐标与基组信息的类型 libcint::CInt。其初始化可以通过下述程序进行:
#![allow(unused)] fn main() { let cint_data = CInt::from_json(&mol_file); }
这里的 mol_file 是定义了分子坐标与基组信息的 json 文件。该文件与 PySCF 输出的格式一致:
# python generation of `mol_file`
from pyscf import gto
mol = gto.Mole(atom="O; H 1 0.94; H 1 0.94 2 104.5", basis="def2-TZVP").build()
with open("h2o-tzvp.json", "w") as f:
f.write(mol.dumps())
RHF 主程序是 minimal_rhf;其输出 RHFResults 定义为
#![allow(unused)] fn main() { pub struct RHFResults { pub mo_coeff: Tsr, pub mo_energy: Tsr, pub dm: Tsr, pub e_nuc: f64, pub e_elec: f64, pub e_tot: f64, } }
2.2 原子核互斥能计算
原子核互斥能的计算代价较小,也有多种实现方案。下面的实现方案并非是性能上最快的,但代码长度少,也比较直观。
首先,通过指标对称性,我们更改原子核互斥能的表达式为
进一步地,我们对下述矩阵作定义:
那么原子核互斥能的表达式会更加简洁:
我们需要得到原子核电荷 。这是一个 的向量。
我们可以用 rt::asarray,生成一个占有数据的张量:
#![allow(unused)] fn main() { let atom_charges = rt::asarray((cint_data.atom_charges(), &device)); // Tsr (natm, ) }
我们需要得到原子核坐标 。这是一个 的矩阵。
CInt::atom_coords 函数输出的是 Vec<[f64; 3]> 类型;它不能由 rt::asarray 直接读取为 f64 类型张量。
#![allow(unused)] fn main() { let coords = cint_data.atom_coords(); // Vec<[f64; 3]> (natm) }
其中一种办法是,先将长度为 的 Vec<[f64; 3]> 类型转换为 Vec<f64> 类型,
#![allow(unused)] fn main() { let coords = coords.into_iter().flatten().collect::<Vec<f64>>(); // Vec<f64> (3 * natm) }
随后代入到 rt::asarray 中构成张量类型 Tsr,并通过 into_shape 重塑其形状为 :
#![allow(unused)] fn main() { rt::asarray((coords, &device)).into_shape((-1, 3)) // Tsr (natm, 3) }
另一种办法是,RSTSR 提供了函数 into_unpack_array;它可以将 [f64; 3] 类型的数据转为 [f64] 类型。其输入的参数是新增加出来的维度的位置 (在当前的例子中,我们希望维度增加在第 1 个位置):
#![allow(unused)] fn main() { let atom_coords = rt::asarray((cint_data.atom_coords(), &device)).into_unpack_array(1); }
对于 ,它实际上就是两个原子之间的 Euclidean 距离。在 RSTSR 的 rt::sci 模块,我们有 cdist 函数以实现该功能 (类比 SciPy cdist 或 Matlab pdist2)。该函数目前还是要求传入张量视窗;视窗可以直接从张量变量后加 .view() 得到。
#![allow(unused)] fn main() { let mut dist = rt::sci::distance::cdist((atom_coords.view(), atom_coords.view())); }
对于 ,它相对于 是在对角线上的值设为无穷大。下述代码中,diagonal_mut 是获得矩阵 的对角线的可变引用,并随后调取 fill 以设置具体的数值。
#![allow(unused)] fn main() { dist.diagonal_mut(None).fill(f64::INFINITY); }
最后,计算总原子核排斥能 的代码为
#![allow(unused)] fn main() { 0.5 * ((atom_charges.i((.., None)) * &atom_charges) / dist).sum() }
该代码用到了张量广播 (broadcast) 的特性。上述表达式在作求和之前,生成的是该张量: 但该数乘计算需要先进行张量的维度对齐才能进行;这是指在 后增加一个维度、并在 前增加一个维度: 不过对于 row-major, 前面增加出来的维度在程序中是可以被识别出来的。因此,我们只需要对 作维度对齐到 即可。
在 RSTSR 中,与 NumPy 一样地,为对齐而扩充维度,可以通过基础索引中插入 None 实现。
2.3 自洽场计算
首先,我们需要获得电子积分。这些量与密度无关,可以事先存储。我们在程序 util.rs (gitee, github) 中封装了电子积分调取函数 intor_row_major,可以在一个函数调用中直接给出 Tsr 张量类型的电子积分。
下述代码中,hcore 为 、ovlp 为 、int2e 为 。
#![allow(unused)] fn main() { let hcore = util::intor_row_major(cint_data, "int1e_kin") + util::intor_row_major(cint_data, "int1e_nuc"); let ovlp = util::intor_row_major(cint_data, "int1e_ovlp"); let int2e = util::intor_row_major(cint_data, "int2e"); }
随后是自洽场循环本身。我们回顾到自洽场问题是为了求解占据轨道系数矩阵 与电子云密度矩阵 ;但由于求解过程中 Fock 矩阵也是随密度有依赖关系的,因此不能一次性计算得到,而需要通过迭代求解得到。该迭代关系总结下来是:
- 通过密度矩阵得到 Fock 矩阵 :
- 对 Fock 矩阵求解本征问题得到轨道系数 ,该轨道系数需要依能级自小到大地排列:
- 取本征值最低的占据轨道数量 个本征向量构成占据轨道系数 ,进而获得密度矩阵 :
自洽场既然是三行公式可以说明的问题,那么程序上也可以用三行写出来:
#![allow(unused)] fn main() { let mut dm = rt::zeros(([nao, nao], &device)); let mut mo_coeff = rt::zeros(([nao, nao], &device)); let mut mo_energy = rt::zeros(([nao], &device)); for _ in 0..NITER { let fock = &hcore + ((1.0_f64 * &int2e - 0.5_f64 * int2e.swapaxes(1, 2)) * &dm).sum_axes([-1, -2]); (mo_energy, mo_coeff) = rt::linalg::eigh((&fock, &ovlp)).into(); dm = 2.0_f64 * mo_coeff.i((.., ..nocc)) % mo_coeff.i((.., ..nocc)).t(); } }
尽管实际上该程序有 8 行,但其中 3 行是对可变变量 dm, mo_coeff, mo_energy 作定义,2 行是构建循环体。因此,真正用于自洽场算法实现的,确实只有 3 行。
#![allow(unused)] fn main() { let fock = &hcore + ((1.0_f64 * &int2e - 0.5_f64 * int2e.swapaxes(1, 2)) * &dm).sum_axes([-1, -2]); }
Fock 矩阵计算中,
int2e.swapaxes(1, 2)是将 4-D 张量 中的 维度作交换,得到 : 在 RSTSR 中,交换两个维度 (swapaxes) 或转置 (transpose) 都是没有计算与内存代价的,但可能对未来的计算效率产生影响;这与 NumPy 或 Julia 是一样的。0.5_f64 * int2e.swapaxes(1, 2)中,我们需要明确定义0.5_f64是 f64 位浮点,而不能仅写为0.5。这是由于 Rust 在处理二目运算类型推断时,左右表达式的地位不等价、以及 RSTSR 内部实现本身有关。该表达式与int2e.swapaxes(1, 2) * 0.5是等价的实现,但后者的写法可以成功地进行类型推断。sum_axes([-1, -2])是对最后两个维度作求和。具体来说,下述代码碎片
执行的是 broadcast 数乘运算,得到了 4-D 张量: 随后对 的最后两个维度 作求和:#![allow(unused)] fn main() { (1.0_f64 * &int2e - 0.5_f64 * int2e.swapaxes(1, 2)) * &dm }- 最后的 Fock 矩阵则通过 得到。
#![allow(unused)] fn main() { (mo_energy, mo_coeff) = rt::linalg::eigh((&fock, &ovlp)).into(); }
广义本征值求解可以通过 RSTSR 的函数 rt::linalg::eigh 实现。
- 该函数返回的值是
EighResult类型,需要通过.into()转换为(Tsr, Tsr)的 tuple 类型。 - 这里由于是改写可变变量
mo_energy,mo_coeff,因此赋值语句左边不需要用 Rust 的 let。
#![allow(unused)] fn main() { dm = 2.0_f64 * mo_coeff.i((.., ..nocc)) % mo_coeff.i((.., ..nocc)).t(); }
密度矩阵计算中,
.i((.., ..nocc))是基础索引语句,它是指对第一个维度作全索引、第二个维度取前 个指标,构成新的矩阵。具体来说,本征值求解得到的矩阵是 大小的 ;但实际的密度矩阵需要前 个本征值最低的本征向量构成的 大小的 。.t()与函数.to_reverse_axes()等价;它是生成一个转置的张量视窗。%是 RSTSR 特有的语法糖;它的意义是矩阵乘法 (或矩阵-向量乘法、向量-矩阵乘法)。RSTSR 中,不论输入的矩阵是 row-major 或 col-major,都可以正常地调用 BLAS 的 GEMM 函数,不会因为输入矩阵是否转置了而产生效率损失。输出矩阵的连续性由编译时设置的 cargo feature (或后端的默认设定) 决定。
2.4 RHF 能量计算
对于 RHF 方法,能量计算的代码与 Fock 矩阵的实现是非常相似的,只是在 4c-2e 双电子积分 上的系数有差异。
#![allow(unused)] fn main() { let eng_scratch = &hcore + ((0.5_f64 * &int2e - 0.25_f64 * int2e.swapaxes(1, 2)) * &dm).sum_axes([-1, -2]); let e_elec = (&dm * &eng_scratch).sum(); let e_tot = e_nuc + e_elec; }
-
这里的表达式可以参考 Szabo & Ostlund, eqs (3.154, 3.184);但需要注意记号上的差异。 ↩
-
这里第第一类是程序意义上的,参考 Lapack
dsygv(参数ITYPE) 或 SciPyeigh(参数type) 程序文档。 ↩
RI-RHF:极简演示
- 程序:
ri_rhf_slow.rs(gitee, github) - 实现内容:RI-RHF (restricted resolution-of-identity Hartree-Fock)
- 不关注程序效率
- 该程序总共约 50 行
在本节中,我们经常将密度矩阵 看作 长度的 1-D 向量,而非 的 2-D 矩阵。类似地,4c-2e 双电子积分经常看作是 的 2-D 矩阵,而非 的 4-D 张量。
目录
1. RI-RHF 回顾
相比于普通的 RHF,RI-RHF 方法不需要计算庞大的 4c-2e 双电子积分,而只需要计算较小的 3c-2e 双电子积分。同时,通过张量分解,其 Fock 矩阵的计算量明显比 RHF 方法小很多。
以 J 积分 为例,RI-V 近似下的 RI-RHF 的理解思路可以大致用下图表示:
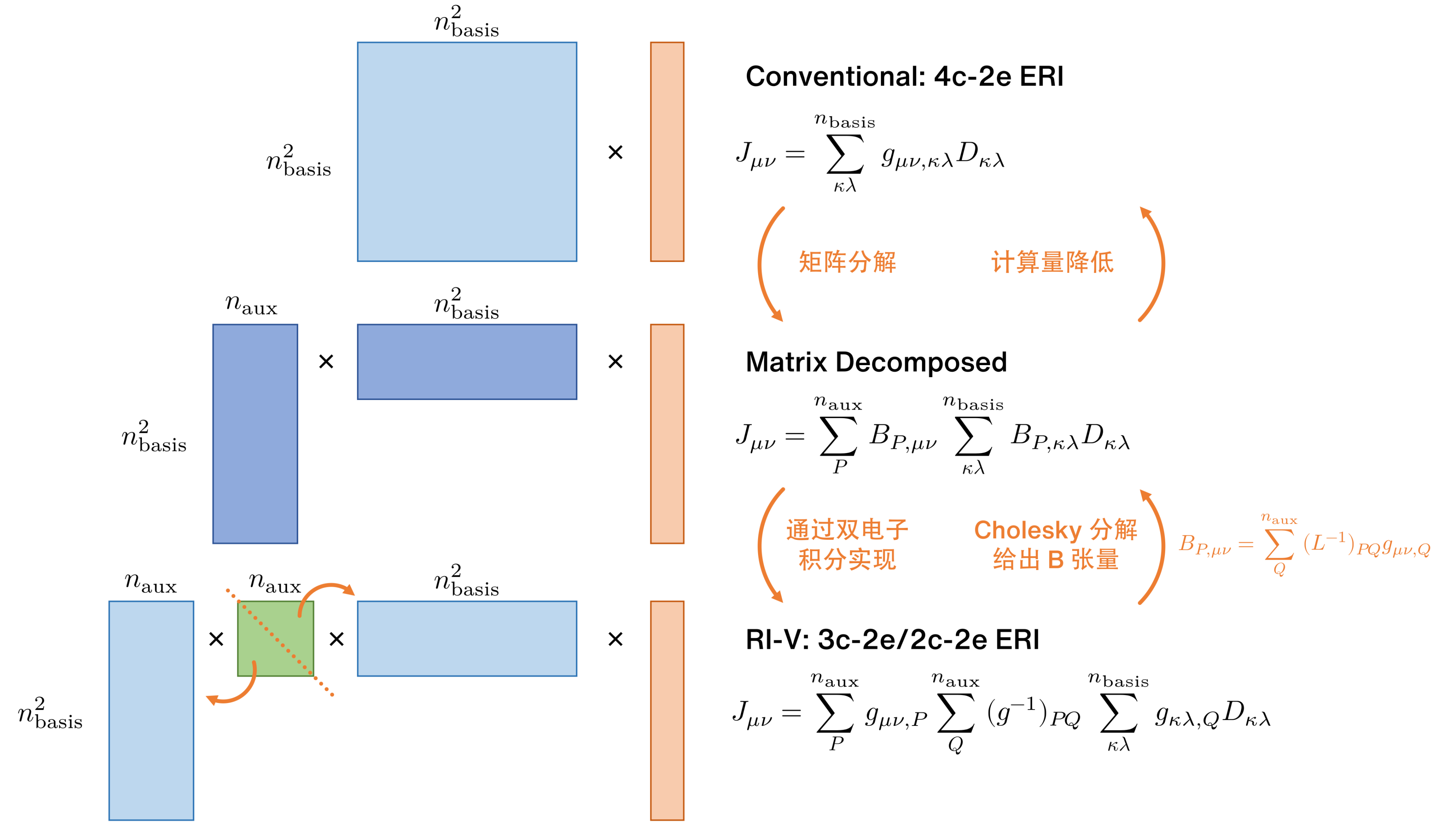
1.1 4c-2e 双电子积分分解
RI-V 近似除了普通的分子轨道基组外,还需要设置辅助基组。辅助基数量越大、精度越高但计算消耗也越多。一般来说,辅助基组的数量 大约是 大小。从矩阵分解的角度来看,如果将 4c-2e 双电子积分看作 的矩阵,那么辅助基的大小 数量级上应该要接近 4c-2e 双电子积分的秩 (rank)。
3c-2e 双电子积分与 2c-2e 双电子积分定义如下:
随后对 2c-2e 双电子积分作 Cholesky 分解,分解得到的 是下三角矩阵:
考虑到 4c-2e 双电子积分在 RI-V 下的近似表达式为
定义 Cholesky 分解量 为 (在我们当前的项目中,需要注意其指标顺序与 3c-2e 双电子积分 不同)
那么 4c-2e 双电子积分的近似表达式也可以写为
1.2 J 积分
J 积分的计算近似为
如果用矩阵-向量乘法来表述,则是
1.3 K 积分
在 RI 近似下,K 积分的计算应代入分子轨道系数以提升计算效率。在闭壳层下,占据轨道总是双占据的。
当我们定义半转换 (half-transformed) 的 为
我们可以将 进一步写为
我们再定义记号 ,这两个张量完全等价。但当作矩阵看待时, 是 大小,而 是 大小。定义 的方便之处在于,K 积分可以用简单的矩阵乘法形式表达出来 (上标 half 是指该张量是经过半转换的):
2. 程序
2.1 4c-2e 双电子积分分解
在获得电子积分后,我们的主要目标是得到 。总共需要作两步计算:Cholesky 分解与矩阵求解:
在程序中的实现如下:
#![allow(unused)] fn main() { let int2c2e_l = rt::linalg::cholesky((int2c2e.view(), Lower)); let cderi = rt::linalg::solve_triangular((int2c2e_l.view(), int3c2e.reshape([nao * nao, naux]).t(), Lower)); let cderi = cderi.into_shape([naux, nao, nao]).into_contig(RowMajor); }
- 关于 Cholesky 分解,代码相信已经很直观了;
- 关于矩阵求解,需要注意到这里的 是下三角矩阵;通过三角矩阵求解函数
solve_triangular会比通常的矩阵求解函数solve_general或者求逆inv函数,性能上要快许多。 - 最后,我们对 作维度修改 (从 的 2-D 矩阵修改到 的 3-D 张量),并从效率角度出发要求该张量需要是 row-major 的 (需要让辅助基指标 是最不连续的维度,这在 K 积分计算中是比较关键的)。
2.2 J 积分
J 积分的过程非常简单,它就是两次矩阵-向量乘法。但需要注意乘法的顺序,否则效率会非常糟糕:
#![allow(unused)] fn main() { let cderi_flat = cderi.reshape([naux, nao * nao]); let dm_flat = dm.reshape([nao * nao]); (cderi_flat.t() % (&cderi_flat % dm_flat)).into_shape([nao, nao]) }
上面的代码花了一些功夫在维度更改上。
2.3 K 积分
K 积分的计算是两次矩阵乘法:
#![allow(unused)] fn main() { let occ_coeff = mo_coeff.i((.., ..nocc)); let scr = (occ_coeff.t() % cderi.reshape([naux * nao, nao]).t()).into_shape([nocc, naux, nao]); let scr_flat = scr.reshape([naux * nocc, nao]); 2.0_f64 * (scr_flat.t() % &scr_flat) }
上述程序的
- 第 1 行是从分子轨道系数中取出占据轨道的部分 ;
- 第 2 行是半转换得到 ;
- 第 3 行是重塑维度得到 ;
- 第 4 行是进行 的实际计算。
这里的程序实现与先前 RI-RHF 回顾中用到的公式还有些许差别。我们需要作一些额外的展开。
第 2 行中,我们实际执行的矩阵乘法是
该矩阵乘法对 重塑维度,并对参与乘法的两个矩阵都作转置,才能得到目标结果。这么做非常费劲,其目的是将半转换后指标 与 联系在一起,方便下面得到矩阵 时可以矩阵乘法一步到位。
由于 中,指标 与 是并在一起的;因此半转换得到的是 还是 并不重要,只要 与 联系在一起即可。
RI-RHF:高效率实现
- 程序:
ri_rhf.rs(gitee, github) - 实现内容:RI-RHF (restricted resolution-of-identity Hartree-Fock)
- 性能尚可
- 体系 (H2O)10 cc-pVDZ (, )
- 计算设备 Ryzen HX7945,16 cores,算力约 1.1 TFLOP/sec
- OpenBLAS 1.4 sec / 16 iter (RSTSR v0.3 的矩阵-向量乘法用 GEMM 而非 GEMV 实现,J 积分较慢)
- Faer 1.3 sec / 16 iter
- 该程序总共约 110 行
- 该程序包含 DIIS 迭代
目录
1. RI-RHF 性能需要考虑的因素
提升 RI-RHF 主要的因素是 3c-2e 双电子积分 与 Cholesky 分解张量 具有对称性: 利用对称性可以节省一半内存,以及减小 J 积分的浮点计算量、以及 K 积分计算时的 DRAM 带宽。
利用对称性当然也可以减少电子积分本身的计算时间;但对于本项目的 RI-RHF 而言,我们已经假定电子积分可以全部存入内存,那么自洽过程就不需要额外计算电子积分了。同时,3c-2e 电子积分计算时间一般不大于一次 SCF 迭代,因此电子积分耗时本来就不是大头。是否节省这点计算量,对于当前项目的算法而言,意义并不大。
Conventional 4c-2e 双电子积分的 RHF 方法体系稍大一些时,内存是无法存入所有电子积分的;因此每次 SCF 迭代一定会重新算电子积分,从而电子积分的耗时变得关键。这与 RI-RHF 的情形并不相同。
2. 3c-2e 双电子积分的获得
我们对 3c-2e 双电子积分有两个考量因素:
- 我们希望 3c-2e 双电子积分只存一半;对于 row-major 情形,我们希望存下三角部分 。
- 考虑到后面
solve_triangular函数的调用,我们希望生成 row-major 下连续的 ,即辅助基的指标是内存上最不连续的。
libcint 给出的 3c-2e 电子积分始终是 形式的,必须要进行一次转置才能得到 。既然我们希望得到的是 row-major 下的 ,那么反过来想,我们可以从 col-major 的 作一次转置,就可以得到 row-major 下的 了。
综合这些考量因素,我们给出如下的 3c-2e 双电子积分计算代码:
#![allow(unused)] fn main() { use libcint::prelude::*; let int3c2e = { let (out, shape) = CInt::integrate_cross("int3c2e", [cint_data, cint_data, aux_cint_data], "s2ij", None).into(); rt::asarray((out, shape.f(), &device)).into_reverse_axes() }; }
CInt::integrate_cross是可以对多个分子基组信息作交叉电子积分计算的函数,其结果是 col-major 的。参数"s2ij"表示其对称性。- 在函数
rt::asarray调用时,使用到的shape.f()是指,在构成张量时,我们希望使用 col-major 布局 (fortran-contiguous)。随后作into_reverse_axes将给出 col-major 到 row-major 的张量转置,这一步不会产生额外的内存复制。 - 最后返回得到的
int3c2e,其布局是 row-major,维度是 ,关于指标 下三角存储。
整个过程中,除了电子积分本身的耗时与内存占用之外,其余部分的资源消耗是近乎为零的。
3. Cholesky 分解张量的获得
#![allow(unused)] fn main() { let cderi = rt::linalg::solve_triangular((int2c2e_l.view(), int3c2e, Lower)); }
这里需要留意的是,我们传入的 int3c2e 是占有数据的 Tsr 张量类型,而不是视窗引用。这意味着变量 int3c2e 在调用 solve_triangular 函数后就无法使用了。这与上一节 ri_rhf_slow.rs 程序的情况不同;上一节的程序的第二个参数 int3c2e.reshape([nao * nao, naux]).t() 是张量视窗。
这里里用到了 RSTSR 的参数重载。当第二个参数 (被求解的长方形矩阵) 是 Tsr 或 TsrMut、而非 TsrView 时,求解得到的结果会被写入到原来的张量中。这种情况下,只要保证传入 solve_triangular 存在一个维度是连续的,不论它是行连续还是列连续,solve_triangular 求解时都不会额外分配内存1。
4. J 积分计算
考虑到对称性,J 积分可以写为
由此,我们可以考虑构建一个缩放后的密度矩阵 ,并在程序实现时只取其下三角部分 :
#![allow(unused)] fn main() { let mut dm_scaled = 2.0_f64 * dm.to_owned(); let dm_diag = dm.diagonal(None); dm_scaled.diagonal_mut(None).assign(dm_diag); let dm_scaled_tp = dm_scaled.pack_tril(); }
随后进行普通的矩阵-向量乘法,得到下三角的 :
#![allow(unused)] fn main() { let j_tp = (&cderi % dm_scaled_tp) % &cderi; }
最后将下三角的 J 积分展开到方形矩阵:
#![allow(unused)] fn main() { j_tp.unpack_tril(FlagSymm::Sy) }
5. K 积分计算
在这里,K 积分的计算与上一节有些许差别。
K 积分计算的核心目的仍然不变,是求取半转换的 Cholesky 分解张量时,尽量将指标辅助基指标 与占据轨道指标 放到一起。但是在放置顺序上,上一篇文档的程序是 ;这里程序的策略则是 。
当前程序的伪代码可以写为
- 对指标 作并行;
- 对特定的指标 ,取得子下三角矩阵 ;
- 对子下三角矩阵 展开到方形矩阵;
- 求取
- 对特定的指标 ,写入 到半转换张量
- 将半转换张量的维度重置为
- 通过矩阵乘法得到
#![allow(unused)] fn main() { let occ_coeff = mo_coeff.i((.., ..nocc)); let scr_xob = unsafe { rt::empty(([naux, nocc, nao], &device)) }; (0..naux).into_par_iter().for_each(|p| { let mut scr_xob = unsafe { scr_xob.force_mut() }; let cderi_ob = cderi.i(p).unpack_tril(FlagSymm::Sy); scr_xob.i_mut(p).matmul_from(&occ_coeff.t(), &cderi_ob, 1.0, 0.0); }); let scr_xob_flat = scr_xob.reshape([naux * nocc, nao]); 2.0_f64 * (scr_xob_flat.t() % &scr_xob_flat) }
程序上,比较特殊的地方有
-
对指标 并行,在 C++/OpenMP 中可以写为
#pragma omp parallel for // if don't want parallel, comment this line for (size_t p = 0; p < naux; ++p) { ... }相对而言,在 Rust 下,使用 Rayon 库,语法上有些许不同,但思路是一样的:
#![allow(unused)] fn main() { // if don't want parallel, change `into_par_iter` to `into_iter` (0..naux).into_par_iter().for_each(|p| { ... }); } -
第一个 unsafe 是
rt::empty的要求。在 Rust 中,声明一块没有初始化的内存是不安全的行为。对于f64类型而言,这个不安全性至多影响到数据安全问题,这在科学计算上不是很重要。但如果是对一个具有析构函数 (traitDropimplemented) 的类型不作初始化,那么很容易会出现非有效内存错误。 -
第二个 unsafe,从程序的角度来说,是强制在每个线程中,对声明为不可变的
scr_xob() 取到其可变的引用。这从一般的程序开发角度来看,是比较危险的 unsafe。但在科学计算问题里,这是非常常见的情况。这个 unsafe 其实在 C++/OpenMP 中是声明某个变量为 shared:
#pragma omp parallel for shared(scr_xob)如果您作为 C++ 编程者,认为这里的 omp shared 语句是可以接受的,那么这里的 unsafe 您也应该容易接受。
-
第二个 unsafe 确实是有更安全的解决方案,但它可能会导致代码变得不那么直观:
#![allow(unused)] fn main() { let mut scr_xob_iter = scr_xob.axes_iter_mut(0); (0..naux).into_par_iter().zip(scr_xob_iter).for_each(|(p, mut scr_ob)| { let cderi_ob = cderi.i(p).unpack_tril(FlagSymm::Sy); scr_ob.matmul_from(&occ_coeff.t(), &cderi_ob, 1.0, 0.0); }); }其中,
axes_iter_mut(0)函数是指对第 0 个维度 (指标 所在的维度) 返回 mutable 子张量的迭代器。这个迭代器可以用于并行的环境。 -
i_mut(p)与i函数一样是基础索引,但它将返回张量的可变视窗。 -
matmul_from与%或者rt::matmul一样,都是张量的矩阵乘法。但不同的是,%与rt::matmul会为矩阵乘法的结果新开辟一片堆空间内存;但matmul_from则是在已有内存上进行矩阵乘法,且允许指定 的系数 与 。使用matmul_from或许从阅读上看来并不直观;但从效率与内存占用上,matmul_from确实是更好的选择。 -
我们在 Rayon 并行区域内调用了矩阵乘法。在 RSTSR 中,对于 BLAS 后端,
- 如果在 Rayon 并行区域外调用 BLAS,则会使用并行版本的 BLAS,并控实际使用的制线程数量。
- 如果在 Rayon 并行区域内调用 BLAS,则会通过
openblas_set_num_threads或omp_set_num_threads控制线程数为 1,从而线程内使用串行的 BLAS、但线程外由 Rayon 控制任务调度,达到并行的效果。 - 对于 pthreads 并行的 OpenBLAS,如果您希望在其他地方直接使用 OpenBLAS 函数前,最好重新通过
openblas_set_num_threads重新设置一下线程数量。Rayon 并行区域内调用 BLAS 可能会破坏 OpenBLAS 的全局并行参数。对于 OpenMP 并行的 OpenBLAS 应没有上述问题。
-
注意到最后实现矩阵乘法 的代码
#![allow(unused)] fn main() { 2.0_f64 * (scr_xob_flat.t() % &scr_xob_flat) }括号影响了计算顺序,即我们需要先进行 ,随后作 2 倍的乘法。如果不加括号,考虑到
*与%是同优先级算符,计算顺序是会发生变化的。同时,对两个相同矩阵的转置乘法 (类似于 或 ),RSTSR 会作一步额外优化:- BLAS 后端会调用 SYRK 而非 GEMM 函数计算;
- Faer 后端会使用仅输出三角矩阵的矩阵乘法模块。 理想情况下,这类型矩阵乘法的浮点计算量相比于普通矩阵乘法,可以节省一半。
-
是否要分配额外的内存,这实际上依赖于后端的实现。不过当前实现了
solve_triangular的后端 Faer 与 OpenBLAS 一般都不会额外分配内存。 ↩
RI-RCCSD:高效率实现
- 程序:
ri_rccsd.rs(gitee, github) - 实现内容:RI-RCCSD (restricted resolution-of-identity coupled-cluster (singles and doubles))
- 性能较高
- 体系 (H2O)10 cc-pVDZ (, ,无冻结轨道)
- 计算设备 Ryzen HX7945,16 cores,算力约 1.1 TFLOP/sec
- 一次 CCSD 迭代约 24.0 sec,CPU 性能利用率约 49%
- 本文档的所有性能分析均基于 OpenBLAS 后端讨论
- 该程序总共约 700 行
- 该程序包含 DIIS 迭代
- 程序测评脚本
cargo build --release --features="use_openblas" target/release/showcase-workshop-rstsr-ricc ri-rccsd \ -mol assets/h2o_10-pvdz.json -aux assets/h2o_10-pvdz_jk.json --aux-ri assets/h2o_10-pvdz_ri.json
目录
- 1. RI-RCCSD 实现前言
- 2. Cholesky 分解积分
- 3. RCCSD 初猜与 RI-RMP2 能量
- 4. RI-RCCSD 中间变量:第一部分
- 5. RI-RCCSD 能量计算
- 6. RI-RCCSD 中间变量:第二部分
- 7. RI-RCCSD 一次激发
rhs1 - 8. RI-RCCSD 二次激发
rhs2: 与类微扰 Fock 矩阵缩并部分 - 9. RI-RCCSD 二次激发
rhs2:直积贡献 - 10. RI-RCCSD 二次激发
rhs2:HHL - 11. RI-RCCSD 二次激发
rhs2:PHL - 12. RI-RCCSD 二次激发
rhs2:PPL - 13. RI-RCCSD 其他计算过程与总结
1. RI-RCCSD 实现前言
相比于 RHF、RI-RHF、RI-CCSD(T) 的 triplet 微扰部分都只有 100 行左右,RI-RCCSD 的 600 行程序长度有明显的提升。这其中直接的原因是
- RI-RCCSD 本身的公式数量相当多;
- 需要用工程化的思路组织程序,这引入了许多不执行具体计算的业务逻辑代码 (大量的 getter/setter);
- 为了提升效率,一些情况下我们确实需要引入更多的代码;
- RSTSR 目前暂不支持 einsum 式的张量缩并1,因此需要用矩阵乘法实现张量缩并。
如果从提升实现效率的角度而言,还有额外的原因是
- 为了将张量缩并问题化为矩阵乘法,我们需要经常思考如何排布张量的指标顺序2。因此,公式推导和程序的实现复杂程度还会进一步提升。
但相对于 RI-RCCSD(T) 的 triplet 微扰,RI-RCCSD 相对来说更简单的部分是
- 绝大多数计算都可以用数学库的标准函数高效实现,不需要作额外的 hack。
我们知道耦合簇方法,从公式上,可以认为是联立下述关于波函数态 方程组,求解 中的激发系数 : 其中,
- 是体系 Hamiltonian,
- 是参考基态 (一般是 Hartree-Fock 基态),
- 是参考方法能级为 的态波函数。 这里指代激发算符;在二次量子化下,一次激发 ,二次激发 。
上式的 原则上应该包含任意阶次的激发算符 (最多到参考态占据电子数),但大多数时候 截断到 2-3 次激发就达到一般化学需求 (或者达到可计算能力上限)。当 截断到二次激发时,称为 CCSD 方法;进一步通过引入 的特定三次微扰时,则称为 CCSD(T) 方法。
耦合簇理论很优美,但程序的实现没办法做得这么漂亮。即使是概述 RI-RCCSD 的实现,也不可避免地涉及大量公式细节3。因此,这一节中,我们会拆解 RI-RCCSD 到数个子任务,对每个子任务进行公式、程序实现、以及性能提升策略的叙述。
2. Cholesky 分解积分
- 程序函数:
get_riccsd_intermediates_cderi
2.1 公式
与 RI-RHF 的情形不同,在 RI-RCCSD 计算时,我们希望辅助基指标在最连续的维度上,且我们希望得到分子轨道基下的 Cholesky 分解积分:
| 变量名 | 公式表达 | 指标 | 维度 |
|---|---|---|---|
b_oo | |||
b_ov | |||
b_vv |
2.2 程序
下述程序从分子基组信息开始,
- 首先获得原子轨道基下的 2c-2e 双电子积分 与 row-major 的 3c-2e 双电子积分 ;
#![allow(unused)] fn main() { let int3c2e = util::intor_3c2e_row_major(cint_data, aux_cint_data, "int3c2e"); let int2c2e = util::intor_row_major(aux_cint_data, "int2c2e"); } - 对原子轨道基下的积分作转换,得到 Cholesky 分解积分 ,
#![allow(unused)] fn main() { let int3c2e_trans = int3c2e.into_shape([nao * nao, naux]).into_reverse_axes(); let int2c2e_l = rt::linalg::cholesky((int2c2e.view(), Lower)); let cderi = rt::linalg::solve_triangular((int2c2e_l.view(), int3c2e_trans, Lower)); let cderi_uvp = cderi.into_reverse_axes().into_shape([nao, nao, naux]); } - 作第一次半转换得到 :
#![allow(unused)] fn main() { let cderi_svp = (mo_coeff.t() % cderi_uvp.reshape((nao, nao * naux))).into_shape((nmo, nao, naux)); } - 对三种情形分别作第二次半转换,得到最终的分子轨道基下的 Cholesky 分解积分;下述计算利用了 RSTSR 所支持的 broadcast 矩阵乘法:
#![allow(unused)] fn main() { let so = slice!(0, nocc); let sv = slice!(nocc, nocc + nvir); let b_oo = mo_coeff.i((.., so)).t() % cderi_svp.i(so); let b_ov = mo_coeff.i((.., sv)).t() % cderi_svp.i(so); let b_vv = mo_coeff.i((.., sv)).t() % cderi_svp.i(sv); }
2.3 性能上的考量
-
与 RI-RHF 实现不同,3c-2e 双电子积分我们要求使用 row-major 的版本得到 ,而不是使用 col-major 的版本再作一次转置得到 。这是因为 RI-RCCSD 的许多计算中,辅助基 是最连续的维度会比较方便。那么不论是 3c-2e 电子积分还是 Cholesky 分解积分,我们都要求辅助基指标 是最连续的。
-
rt::linalg::solve_triangular支持 inplace solve (上述代码的cderi复用了int3c2e_trans的内存数据,效率更高),因此对int3c2e的维度更改操作,始终使用into_函数 (输入输出都是占据数据的张量),而不是使用视窗。 -
我们需要存储三个分子轨道基 Cholesky 分解积分 、、。一个自然的疑问是,为什么我们不存储完整的分子轨道空间积分 ?这会牺牲不是很多的内存,但可以减少程序用到的变量数量,简化程序编写。
但考虑到后续的计算过程中,经常要作 reshape 维度更改 (譬如 )。而维度更改要求了数据的连续性 (该例子中,如果要求维度更改不会产生新的内存, 与 指标未必是连续的,但 和 之间必须是连续的)。
这意味着,如果存储为 row-major 连续的 ,那么取 时是不会发生内存复制的:
#![allow(unused)] fn main() { b_oo.reshape((nocc, nocc * naux)) // DataCow::Ref, data not cloned }如果存储为 、而在用到子张量 时使用索引加 reshape,是会发生内存复制的:
#![allow(unused)] fn main() { b_all.i((so, so, ..)).reshape((nocc, nocc * naux)) // DataCow::Owned, data cloned }考虑到 到 这类 reshape 经常会用到,我们不能只存一个变量 而需要分开存三个,为运行效率对代码复杂度作妥协。
3.4 性能评价
| 计算过程 | FLOPs 解析式 | FLOPs 实际数值 | 计算耗时 |
|---|---|---|---|
| 3c-2e/2c-2e 双电子积分 | 85 msec | ||
| Cholesky 分解积分 | 38.0 GFLOPs | 85 msec | |
| 原子轨道到分子轨道变换 | 39.7 GFLOPs | 250 msec |
- Cholesky 分解积分的浮点效率是 0.45 TFLOP/sec,性能利用率 40%,其性能是比较高的;
- 原子轨道到分子轨道变换的浮点效率是 0.16 TFLOP/sec,性能利用率 14%,该步骤性能有待改进;但考虑到 CCSD 中分子轨道变换占总计算消耗很少,因此仅针对当前任务,不是非常有必要对该过程进一步优化:
- 上述计算过程没有利用电子积分的对称性,内存利用上有少许提升空间;
- 上述代码的实现较为简洁,但诸如
cderi_svp等中间张量其实是可以避免生成、从而避免较大的内存带宽消耗。原子轨道到分子轨道变换的性能有进一步提升的空间。
3. RCCSD 初猜与 RI-RMP2 能量
- 程序函数:
get_riccsd_initial_guess - 输出类型:
RCCSDResults
CCSD 的初猜一般是 MP2 的激发振幅;在真正开始 CCSD 计算前,由于 MP2 能量计算并不额外消耗太多计算资源,因此 RI-RMP2 能量可以顺便给出。
3.1 输出类型 RCCSDResults
#![allow(unused)] fn main() { pub struct RCCSDResults { pub e_corr: f64, pub t1: Tsr, pub t2: Tsr, } }
| 变量名 | 公式表达 | 指标 | 维度 |
|---|---|---|---|
t1 | |||
t2 | |||
e_corr | scalar |
上表中, 是指 CCSD 的相关能;只有与 Hartree-Fock 参考态能量求和,才得到完整的 CCSD 体系能量。
3.2 公式
首先,为计算 MP2 的二次激发张量 ,需要获得分子轨道下的 4c-2e 双电子积分 ,求得多体微扰分母 :
随后可以计算 MP2 能量 (下式的 OS 表示 opposite-spin、SS 表示 same-spin,bi1 与 bi2 表示闭壳层 bi-orthogonal 下的两个分量):
3.3 程序
MP2 的激发张量与能量可以在 3-5 行公式内写出,意味着程序也可以在 3-5 行代码 (或 3-5 个 statement) 实现 (下述代码片段中张量的指标顺序是 ,与正文其他部分不同):
#![allow(unused)] fn main() { let g2 = b_ov.reshape((nocc * nvir, -1)) % b_ov.reshape((nocc * nvir, -1)).t(); let g2 = g2.into_shape((nocc, nvir, nocc, nvir)); let d2 = mo_energy.i((so, None, None, None)) - mo_energy.i((None, sv, None, None)) + mo_energy.i((None, None, so, None)) - mo_energy.i((None, None, None, sv)); let t2 = &g2 / &d2; let e_corr_mp2 = ((2.0_f64 * &t2 - t2.swapaxes(1, 3)) * &g2).sum(); }
这段程序尽管非常直观短小,但计算量与内存消耗都较大。实际运行的程序是
#![allow(unused)] fn main() { let d_ov = mo_energy.i((so, None)) - mo_energy.i((None, sv)); let t1 = rt::zeros(([nocc, nvir], &device)); let t2 = rt::zeros(([nocc, nocc, nvir, nvir], &device)); let e_corr_oo = rt::zeros(([nocc, nocc], &device)); (0..nocc).into_par_iter().for_each(|i| { (0..i + 1).into_par_iter().for_each(|j| { let g2_ab = b_ov.i(i) % b_ov.i(j).t(); let d2_ab = d_ov.i((i, .., None)) + d_ov.i((j, None, ..)); let t2_ab = &g2_ab / &d2_ab; let mut t2 = unsafe { t2.force_mut() }; t2.i_mut((i, j)).assign(&t2_ab); if i != j { t2.i_mut((j, i)).assign(&t2_ab.t()); } let e_bi1 = (&t2_ab * &g2_ab).sum_all(); let e_bi2 = (&t2_ab * &g2_ab.swapaxes(-1, -2)).sum_all(); let e_corr_ij = 2.0 * e_bi1 - e_bi2; let mut e_corr_oo = unsafe { e_corr_oo.force_mut() }; *e_corr_oo.index_mut([i, j]) = e_corr_ij; *e_corr_oo.index_mut([j, i]) = e_corr_ij; }); }); let e_corr = e_corr_oo.sum_all(); }
上述代码可以利用输出张量 的对称性,从而只对 的下三角情形作计算;而上三角的部分复制下三角的部分即可,减少一半计算量。
3.4 性能评价
| 计算过程 | FLOPs 解析式 | FLOPs 实际数值 |
|---|---|---|
| 70.6 GFLOPs |
- 该计算总浮点计算量大于 70.6 GFLOPs;
- 计算耗时约 180 msec,实际运行效率不低于 0.39 TFLOP/sec;
- CPU 性能利用率不少于 36%。
这个性能利用率可以接受但不算很高,说明如下:
- 在确定计算量时,我们没有统计入其他 的部分;
- 如果仅仅是计算 MP2 能量,那么 MP2 激发张量 不需要写入到内存;但作为 CCSD 计算任务的初猜过程,这个较大张量的写入是必须的,从而有额外的内存读写的开销。这应当是主要的效率影响因素。若不需要在内存写入 张量,则 CPU 性能利用率可能达到 50%。
- 在计算浮点计算量 FLOPs 数值时,我们只考虑了 4c-2e 双电子积分 的部分,而没有考虑 MP2 能量计算;因此上面的 CPU 性能利用率是被低估的。同时,像
&t2_ab * &g2_ab与&t2_ab * &g2_ab.swapaxes(-1, -2)这类运算会开辟新的内存空间;但我们的目标其实是求和得到能量,这里开辟出新的空间是浪费内存带宽的。因此这里的 MP2 能量计算性能有进一步提升的空间,但提升空间并不大 (可能到 60%)。
4. RI-RCCSD 中间变量:第一部分
- 程序函数:
get_riccsd_intermediates_1
4.1 RI-RCCSD 中间变量
RI-RCCSD 有许多中间变量;在一次 CCSD 迭代中,这些中间变量会被多次使用到,因此需要找内存空间存储起来。
从程序实现角度,RI-RCCSD 的中间变量分为两部分:一部分是计算 CCSD 相关能时需要用到的中间量,另一部分是只在更新 、 时才会用的中间量。
中间变量的命名规则是
- 中间变量字母记为 ;
- 数字 1、2 分别代表中间变量中包含的激发次数;
- 如果有多种意义不同、但包含激发次数相同的中间变量,则以
a,b等进行区分; - RI-RCCSD 用到的中间变量大多是 3-D 张量,但也有其他维度张量。变量最后的字母
o表示占据轨道维度,v表示非占轨道维度,j表示辅助基维度。
4.2 公式
| 变量名 | 公式表达 | 指标 | 维度 |
|---|---|---|---|
m1_j | |||
m1_oo | |||
m2a_ov |
需要留意, 不具有占据轨道上的对称性,即一般来说 。
4.3 程序
#![allow(unused)] fn main() { let m1_j = t1.reshape(-1) % b_ov.reshape((-1, naux)); let m1_oo: Tsr = rt::zeros(([nocc, nocc, naux], &device)); (0..nocc).into_par_iter().for_each(|j| { let mut m1_oo = unsafe { m1_oo.force_mut() }; *&mut m1_oo.i_mut((.., j)) += &t1 % &b_ov.i(j); }); let m2a_ov: Tsr = rt::zeros(([nocc, nvir, naux], &device)); (0..nocc).into_par_iter().for_each(|i| { let mut m2a_ov = unsafe { m2a_ov.force_mut() }; let scr_jba: Tsr = 2 * t2.i((.., i)) - t2.i(i); *&mut m2a_ov.i_mut(i) += scr_jba.reshape((-1, nvir)).t() % b_ov.reshape((-1, naux)); }); }
4.4 性能上的考量
-
矩阵乘法的实现:上述计算都使用
%即普通的矩阵乘法得到新的张量后,通过*&mut var += new_mat进行赋值。这种赋值语句可能比较直观,但由于产生额外的内存开销,性能上会比var.matmul_from(a, b, alpha, beta)要低一些。 -
特定情景下不使用 broadcast 矩阵乘法:计算
m1_oo时,对指标 作手动并行。这里使用 broadcast 矩阵乘法会导致内存连续性问题,不适合用一行代码直接实现该矩阵乘法。 -
避免大量中间内存的考量:计算
m2a_ov时,对指标 作手动并行。这里并行的目的是避免直接生成 4-D 张量 ,而是在每个线程中生成一个 3-D 的、固定了指标 数值的张量 ,较大的内存开销。- 尽管在 RI-RCCSD 中间张量计算中,我们可以通过这种方式避免大量中间内存;但在后续计算过程中,若要使得效率最大化,我们似乎不太能避免产生一些新的 浮点数大小的中间张量。
-
为性能考量而更改公式表达:计算
m2a_ov时,程序与公式的结果等价,但具体的做法上有差异。-
更改中间张量指标顺序:我们注意到 在固定特定的指标 时,正常情况下应该是 的 3-D 张量:
#![allow(unused)] fn main() { let scr_jab: Tsr = 2 * t2.i(i) - t2.i(i).swapaxes(2, 3); }但考虑到后续要将其与 作张量缩并,其被缩并的指标是 ,那么将张量缩并归约到矩阵乘法时,应该要是 或 ;但这要求的是一个 即 或 即 的 3-D 张量。无论是 还是 ,这都与 通常存储的顺序 不一致。
既然 只是一个中间张量,我们不见得就要严格按照既定的公式与程序约定俗成来实现该变量。在当前程序实现里,我们直接实现转置了指标的 张量 :
#![allow(unused)] fn main() { let scr_jba: Tsr = 2 * t2.i(i).swapaxes(2, 3) - t2.i(i); } -
考虑 Elementwise 操作的连续性:我们还注意到上述实现与实际的程序实现并不相同:
#![allow(unused)] fn main() { // let scr_jba: Tsr = 2 * t2.swapaxes(0, 1).i(i) - t2.i(i); // equilvant code to below let scr_jba: Tsr = 2 * t2.i((.., i)) - t2.i(i); }实际程序中使用到的公式是
这是里用到了 的二重对称性。注意到在 row-major 下, 与 在内存中,共同最大连续维度是指标 对应的维度,其长度是 ;处理这两个张量之间的 elementwise 运算时,由于内存的连续性,其性能较高。而 与 在内存中,没有共同的连续维度;处理这两个张量之间的 elementwise 运算,性能会比较低。
-
4.4 性能评价
| 计算过程 | FLOPs 解析式 | FLOPs 实际数值 |
|---|---|---|
| 0.01 GFLOPs | ||
| 0.74 GFLOPs | ||
| 141.21 GFLOPs |
- 该计算总浮点计算量约 142 GFLOPs;
- 计算耗时约 320 msec,实际运行效率为 0.44 TFLOP/sec;
- CPU 性能利用率为 40%。
5. RI-RCCSD 能量计算
- 程序函数:
get_riccsd_energy
在有了一些中间变量后,我们可以计算 RI-RCCSD 能量:
在合理的 reshape 下,程序实现也比较直观:
#![allow(unused)] fn main() { let e_t1_j = 2.0_f64 * (m1_j % m1_j); let e_t1_k = -(m1_oo.reshape(-1) % m1_oo.swapaxes(0, 1).reshape(-1)); let e_t2 = b_ov.reshape(-1) % m2a_ov.reshape(-1); let e_corr = e_t1_j + e_t1_k + e_t2; e_corr.to_scalar() }
需要留意,在 RSTSR 下,向量-向量点乘得到的结果仍然是张量,需要通过 to_scalar 函数返回一个 f64 浮点数。
该计算耗时约为 5 msec,相比于其他过程完全是可以忽略的,没有必要讨论其计算性能。
6. RI-RCCSD 中间变量:第二部分
- 程序函数:
get_riccsd_intermediates_2
6.1 公式
第二部分中间变量不会在能量计算中用到,但会在更新激发张量 与 时会用到。
| 变量名 | 公式表达 | 指标 | 维度 |
|---|---|---|---|
m1a_ov | |||
m1b_ov | |||
m1_vv | |||
m2b_ov |
6.2 程序
#![allow(unused)] fn main() { let m1a_ov = rt::zeros(([nocc, nvir, naux], &device)); (0..nocc).into_par_iter().for_each(|i| { let mut m1a_ov = unsafe { m1a_ov.force_mut() }; *&mut m1a_ov.i_mut(i) += t1.t() % &b_oo.i(i); }); let m1b_ov = &t1 % b_vv.reshape((nvir, -1)); let m1b_ov = m1b_ov.into_shape((nocc, nvir, naux)); let m1_vv = t1.t() % b_ov.reshape((nocc, -1)); let m1_vv = m1_vv.into_shape((nvir, nvir, naux)); let m2b_ov = rt::zeros(([nocc, nvir, naux], &device)); (0..nocc).into_par_iter().for_each(|i| { let mut m2b_ov = unsafe { m2b_ov.force_mut() }; *&mut m2b_ov.i_mut(i) += t1.t() % m1_oo.i(i); }); }
上述实现中,在 m1b_ov 中我们里用到了 的对称性。
RI-RCCSD 中间变量的第二部分的耗时大约是 60 msec,其耗时非常少,我们也就不讨论其性能了。
7. RI-RCCSD 一次激发 rhs1
- 程序函数:
get_riccsd_rhs1
7.1 公式
我们令 是 RI-RCCSD 用于更新一次激发振幅公式的等式右。其中, 是轨道能级差。
CCSD 的激发振幅表达式都比较复杂,且未必只有一种实现方式。在当前程序中,我们将其分为 5 部分:
7.2 程序
#![allow(unused)] fn main() { // === TERM 1 === // let mut scr_kc: Tsr = rt::zeros(([nocc, nvir], &device)); for l in 0..nocc { scr_kc += m1_oo.i(l) % b_ov.i(l).t(); } (0..nocc).into_par_iter().for_each(|i| { let mut rhs1 = unsafe { rhs1.force_mut() }; let mut t2_i: Tsr = 2.0 * t2.i(i) - t2.i((.., i)); t2_i *= scr_kc.i((.., None, ..)); *&mut rhs1.i_mut(i) -= t2_i.sum_axes([0, 2]); }); // === TERM 2 === // rhs1 -= (m2a_ov - m1a_ov).reshape((nocc, -1)) % b_ov.reshape((nocc, -1)).t() % t1; // === TERM 3 === // rhs1 += m2a_ov.reshape((nocc, -1)) % b_vv.reshape((nvir, -1)).t(); // === TERM 4 === // for k in 0..nocc { rhs1 -= (b_oo.i(k) + m1_oo.i((.., k))) % (m2a_ov.i(k) + m1b_ov.i(k)).t(); } // === TERM 5 === // let scr_iaP: Tsr = b_ov + m1b_ov - m1a_ov + m2a_ov - 0.5 * m2b_ov; rhs1 += 2.0 * (scr_iaP.reshape((-1, naux)) % m1_j).reshape((nocc, nvir)); }
对于第 1、2 项的连续张量缩并,我们需要将其分解为多个矩阵乘法任务。
RI-RCCSD 一次激发的 rhs1 的总计算耗时约 200 msec。由于该计算耗时并不大、但公式繁杂,我们也不对该步骤进行性能分析了。
8. RI-RCCSD 二次激发 rhs2: 与类微扰 Fock 矩阵缩并部分
- 程序函数:
get_riccsd_rhs2_lt2_contract
自此开始的 5 个小节将展开 RI-RCCSD 中计算量瓶颈部分:RI-RCCSD 二次激发 rhs2 的计算:
请留意这里上式左边的转置求和。后续的计算中,我们只计算 ,而 是通过维度转置得到的。当在 CCSD 迭代中更新 时,我们用到的表达式是
可以分为 5 个部分构成;其中一些贡献项满足 对称性 (包括 HHL, PPL),但也有一些贡献项是不满足二重对称性的 (类微扰 Fock 缩并贡献、直积贡献、PHL)。
我们将大致依计算量从小到大的顺序,在 5 个小节中分别实现与讨论二次激发表达式 的计算过程。
8.1 公式
首先定义一种类似于 Fock 矩阵微扰的量 与 (但准确来说只是为了编写程序方便、或为节省计算量而设立的临时变量):
随后将 、 与 作指标缩并,得到 rhs2 的贡献项:
8.2 程序
#![allow(unused)] fn main() { // occ-occ part of L let mut l_oo = m2a_ov.reshape((nocc, -1)) % b_ov.reshape((nocc, -1)).t(); let scr: Tsr = 2 * b_oo + m1_oo; l_oo += (scr.reshape((-1, naux)) % m1_j).into_shape((nocc, nocc)); for l in 0..nocc { l_oo -= b_oo.i(l) % m1_oo.i(l).t(); } let mut rhs2 = rt::asarray((rhs2.raw_mut(), [nocc, nocc * nvir * nvir].c(), &device)); rhs2.matmul_from(&l_oo, &t2.reshape((nocc, -1)), -1.0, 1.0); // vir-vir part of L let scr: Tsr = 2 * b_vv - m1_vv; let mut l_vv = (scr.reshape((-1, naux)) % m1_j).into_shape((nvir, nvir)); for k in 0..nocc { l_vv -= (m2a_ov.i(k) + m1b_ov.i(k)) % b_ov.i(k).t(); } let mut rhs2 = rt::asarray((rhs2.raw_mut(), [nocc * nocc * nvir, nvir].c(), &device)); rhs2.matmul_from(&t2.reshape((-1, nvir)), &l_vv.t(), 1.0, 1.0); }
上述程序中,
-
注意到其中有两处循环
for l in 0..nocc与for k in 0..nocc都没有开启并行。由于这些循环都是更新整个 与 ,如果强制并行且可变地写入l_oo与l_vv会导致线程竞态 (racing condition)。上述线程竞态的一种解决方案是基于 rayon 并行框架下以 fold 函数实现多个线程的 、 的累加。
但考虑到一方面是因为它们是 的矩阵乘法运算,计算消耗较低,不需要进行更复杂的优化、矩阵乘法本身的并行可以交给 BLAS 后端。
-
实现下述表达式的最直观的程序是
#![allow(unused)] fn main() { rhs2 -= (l_oo % t2.reshape((nocc, -1))).into_shape((nocc, nocc, nvir, nvir)); }这会导致大量内存带宽的消耗:首先矩阵乘法要生成一个新的大张量,随后这个大张量要与
rhs2作 elementwise 减法。这两步都是有较大性能损耗的。一般来说,如果矩阵乘法的目的是要累加到另一个矩阵、且该计算是瓶颈,那么应该尽量使用可以作 inplace 运算的matmul_from函数,而避免直接使用%或matmul等 outplace 函数。但这又带来另一个问题:
rhs2按理应该是 的 4-D 张量,但是matmul_from只能接受 2-D 的矩阵。因此,我们要更改程序变量rhs2的维度到 2-D。但reshape通常生成的是不可变的张量视窗 (严格来说是 copy-on-write 类型),into_shape生成的是一个新的占有数据的张量;两种情形都不是我们希望看到的。在 RSTSR 中,一种解决办法是使用rt::asarray函数,传入新的张量维度信息,生成一个新的可变张量视窗。以当前的例子来看,我们希望将上述矩阵乘法问题写为在确保前后张量都是 row-major 连续的前提下,就传入
&mut Vec<f64>类型的引用、新的 2-D 矩阵维度 的布局、以及后端信息到rt::asarray,就可以得到新的可变张量视窗:#![allow(unused)] fn main() { let mut rhs2 = rt::asarray((rhs2.raw_mut(), [nocc, nocc * nvir * nvir].c(), &device)); }随后就可以用
matmul_from作 inplace 矩阵乘法与累加了。
8.3 性能评价
| 计算类型 | 计算过程 | FLOPs 解析式 | FLOPs 实际数值 |
|---|---|---|---|
| 0.74 GFLOPs | |||
| 0.20 GFLOPs | |||
| 可以忽略 | |||
| 2.82 GFLOPs | |||
| 可以忽略 | |||
| 8.41 GFLOPs | |||
| 31.94 GFLOPs | |||
| 总计 | 44.11 GFLOPs |
- 计算耗时约 290 msec,实际运行效率为 0.15 TFLOP/sec;
- CPU 性能利用率为 14%。
这里的 CPU 性能利用率较低。我们认为可能的原因是,
- 这一步计算尽管浮点计算量很少,但它实际上是内存瓶颈计算。
- 诸如 、 等中间变量需要分配与占用不少内存带宽。
9. RI-RCCSD 二次激发 rhs2:直积贡献
- 程序函数:
get_riccsd_rhs2_direct_dot
9.1 公式
9.2 程序
#![allow(unused)] fn main() { let scr_iaP: Tsr = b_ov + m2a_ov; let scr_jbP: Tsr = 0.5 * b_ov + 0.5 * m2a_ov - m1a_ov + m1b_ov - m2b_ov; (0..nocc).into_par_iter().for_each(|i| { (0..nocc).into_par_iter().for_each(|j| { let mut rhs2 = unsafe { rhs2.force_mut() }; *&mut rhs2.i_mut((i, j)) += scr_iaP.i(i) % scr_jbP.i(j).t(); *&mut rhs2.i_mut((i, j)) -= m1a_ov.i(i) % m1b_ov.i(j).t(); }); }); }
9.3 性能评价
- 这里的计算公式看起来很复杂,但除去张量 elementwise 加法,真正的计算瓶颈是两个 的过程。
- FLOPs 解析式 ,FLOPs 实际数值 282.4 GFLOPs。
- 计算耗时约 400 msec,实际运行效率为 0.71 TFLOP/sec;
- CPU 性能利用率为 64%。
10. RI-RCCSD 二次激发 rhs2:HHL
- 程序函数:
get_riccsd_rhs2_o4v2 - 该项 (hole-hole ladder) 的渐进复杂度是
10.1 公式
10.2 程序
下述程序中,
scr_ijkl第一块代码实现的是 ;scr_klcd实现的是 ;scr_ijkl第二块代码实现了累加 ;rhs2第一次更改实现的是 ;rhs2第一次更改实现的是 。
需要作的补充说明是
- 该程序尚未充分利用对称性:需要注意到,输出张量
rhs2与中间变量scr_ijkl、scr_klcd都具有二重对称性;但实际程序实现中,上述 5 个步骤只有前两步利用到了对称性。后 3 步的对称性原则上也可以实现 (参考 PPL 项的实现过程),但对于小体系而言 HHL 充分利用对称性的意义有限。 - 该程序没有直接计算得到 ,而是将两项分别与 作张量缩并;这样可以减少一个 的临时张量,同时也没有增加太多计算量。
#![allow(unused)] fn main() { let scr_bm1_oo = b_oo + m1_oo; let mut scr_ijkl: Tsr = rt::zeros(([nocc, nocc, nocc, nocc], &device)); (0..nocc).into_par_iter().for_each(|i| { (0..i + 1).into_par_iter().for_each(|j| { let mut scr_ijkl = unsafe { scr_ijkl.force_mut() }; let scr = scr_bm1_oo.i(i) % scr_bm1_oo.i(j).t(); *&mut scr_ijkl.i_mut((i, j)) += &scr; if i != j { *&mut scr_ijkl.i_mut((j, i)) += scr.t(); } }); }); let scr_klcd: Tsr = rt::zeros(([nocc, nocc, nvir, nvir], &device)); (0..nocc).into_par_iter().for_each(|k| { (0..k + 1).into_par_iter().for_each(|l| { let mut scr_klcd = unsafe { scr_klcd.force_mut() }; let scr = b_ov.i(k) % b_ov.i(l).t(); *&mut scr_klcd.i_mut((k, l)) += &scr; if k != l { *&mut scr_klcd.i_mut((l, k)) += scr.t(); } }); }); let mut scr_ijkl_mut = rt::asarray((scr_ijkl.raw_mut(), [nocc * nocc, nocc * nocc].c(), &device)); scr_ijkl_mut.matmul_from(&t2.reshape((nocc * nocc, -1)), &scr_klcd.reshape((nocc * nocc, -1)).t(), 1.0, 1.0); // t1 contraction to rhs2 (0..nocc).into_par_iter().for_each(|i| { (0..nocc).into_par_iter().for_each(|j| { let mut rhs2 = unsafe { rhs2.force_mut() }; *&mut rhs2.i_mut((i, j)) += 0.5 * t1.t() % scr_ijkl.i((i, j)) % &t1; }); }); // t2 contraction to rhs2 let mut rhs2 = rt::asarray((rhs2.raw_mut(), [nocc * nocc, nvir * nvir].c(), &device)); rhs2.matmul_from(&scr_ijkl.reshape((nocc * nocc, -1)), &t2.reshape((-1, nvir * nvir)), 0.5, 1.0); }
10.3 性能评价
| 计算类型 | 计算过程 | FLOPs 解析式 | FLOPs 实际数值 | 可能的提升空间 |
|---|---|---|---|---|
| 4.9 GFLOPs | ||||
| 70.6 GFLOPs | ||||
| 420.3 GFLOPs | 对称性减半 | |||
| 10.6 GFLOPs | 内存换计算量 | |||
| 420.3 GFLOPs | 对称性减半 | |||
| 总计 | 0.93 TFLOPs |
- 计算耗时约 1.6 sec,实际运行效率为 0.58 TFLOP/sec;
- CPU 性能利用率为 53%。
11. RI-RCCSD 二次激发 rhs2:PHL
- 程序函数:
get_riccsd_rhs2_o3v3 - 该项 (particle-hole ladder) 的渐进复杂度是
- 尽管 PHL 项比 HHL 项的渐进复杂度 ,但计算耗时实际上是接近的
11.1 公式
PHL 项的 RI 实现需要定义非常多的中间张量:
这里的公式与程序实现比较接近,您可以注意到指标的顺序已经经过整理,使得张量缩并计算已经可以用普通的矩阵乘法表示。
11.2 程序
该程序的公式与中间张量明显增多,但我们会注意到除了 里用到张量对称性简化计算、而产生了更多代码之外,每个单步计算都是简单的矩阵乘法。并且 PHL 项其他部分几乎不能利用对称性以简化计算,因此没有什么特殊的技巧可以用来加速程序效率。实际上 PHL 项的程序并不长,也相对比较直观:
#![allow(unused)] fn main() { let scr_ikP = b_oo + m1_oo; let scr_acP = b_vv - m1_vv; let scr1: Tsr = rt::zeros(([nocc, nocc, nvir, nvir], &device)); (0..nocc).into_par_iter().for_each(|k| { (0..k + 1).into_par_iter().for_each(|l| { let mut scr1 = unsafe { scr1.force_mut() }; let scr = b_ov.i(k) % b_ov.i(l).t(); scr1.i_mut((k, l)).assign(&scr); if k != l { scr1.i_mut((l, k)).assign(scr.t()); } }); }); (0..nocc).into_par_iter().for_each(|i| { let t2t_i = t2.swapaxes(0, 1).i(i).into_contig(RowMajor); let scr2 = rt::zeros(([nocc, nvir, nvir], &device)); let scr3 = rt::zeros(([nocc, nvir, nvir], &device)); let scr4 = rt::zeros(([nocc, nvir, nvir], &device)); (0..nocc).into_par_iter().for_each(|k| { let mut scr2 = unsafe { scr2.force_mut() }; let mut scr3 = unsafe { scr3.force_mut() }; scr2.i_mut(k).matmul_from(&scr1.i(k).reshape((-1, nvir)).t(), &t2.i(i).reshape((-1, nvir)), 1.0, 0.0); scr3.i_mut(k).matmul_from(&scr1.i(k).reshape((-1, nvir)).t(), &t2t_i.reshape((-1, nvir)), 1.0, 0.0); }); (0..nvir).into_par_iter().for_each(|c| { let mut scr4 = unsafe { scr4.force_mut() }; scr4.i_mut((.., c)).matmul_from(&scr_ikP.i(i), &scr_acP.i((.., c)).t(), 1.0, 0.0); }); let scr5: Tsr = -scr3 - &scr4 + &scr2; let scr6: Tsr = -scr4 + 0.5 * &scr2; (0..nocc).into_par_iter().for_each(|j| { let mut rhs2 = unsafe { rhs2.force_mut() }; for k in 0..nocc { rhs2.i_mut((i, j)).matmul_from(&scr5.i(k).t(), &t2.i((k, j)), 1.0, 1.0); rhs2.i_mut((i, j)).matmul_from(&t2.i((j, k)).t(), &scr6.i(k), 1.0, 1.0); } }); }); }
11.3 性能与程序结构上的考量
上述程序需要作说明的地方有
-
在程序中,我们总是用
scr前缀加数字后缀表示上式中 有关的张量。 -
这段程序的矩阵乘法都使用了
matmul_from;这种代码可能不太直观,但可以避免额外的内存带宽。 -
我们尽可能地避免了 的中间张量。在程序中,除了
scr1之外,其余的部分都是以占据轨道指标 进行分批的 大小的 3-D 张量。scr1较大的 储存空间实际上也是可以避免的。如果整个程序对占据轨道指标 作嵌套循环 (nested loop),整体的计算量会增加、但不会增加太多,且可以避免所有 的额外张量存储。
-
变量
t2t_i是 在特定 指标下的 3-D 张量,其形状是 所指代的 。但要注意到尽管t2.swapaxes(0, 1).i(i)这个操作本身是没有性能损耗的、但输出的不可变张量视窗并不是 row-major 连续的;后续我们要将该张量作形状更改 (reshape((-1, nvir))) 到 的矩阵,对于不连续的张量的形状更改是要作内存复制的。因此,我们希望用 作计算时,尽量要让它是连续的。这段程序作的妥协是,在关于占据轨道指标 作并行前,对 在特定 指标下的 3-D 张量内存复制到 row-major 连续。这样的话,总的内存带宽占用量是 。
#![allow(unused)] fn main() { // memory bandwidth consumption: occ^2 vir^2 ~ N^4 (0..nocc).into_par_iter().for_each(|i| { let t2t_i = t2.swapaxes(0, 1).i(i).into_contig(RowMajor); // copy before inner `k` loop (0..nocc).into_par_iter().for_each(|k| { t2t_i.reshape((-1, nvir)) // this line does not perform memory copy of underlying data }如果我们不明确地将 复制到一个新的 row-major 张量,那么代码看起来少了,但内存带宽占用量会上升到 :
#![allow(unused)] fn main() { // memory bandwidth consumption: occ^3 vir^2 ~ N^5 (0..nocc).into_par_iter().for_each(|i| { (0..nocc).into_par_iter().for_each(|k| { t2.swapaxes(0, 1).i(i).reshape((-1, nvir)) // this line COPIES of underlying data }
11.4 性能评价
| 计算类型 | 计算过程 | FLOPs 解析式 | FLOPs 实际数值 |
|---|---|---|---|
| 0.07 TFLOPs | |||
| 1.56 TFLOPs | |||
| 1.56 TFLOPs | |||
| 0.14 TFLOPs | |||
| 1.56 TFLOPs | |||
| 1.56 TFLOPs | |||
| 总计 | 6.45 TFLOPs |
- 计算耗时约 10.0 sec,实际运行效率为 0.65 TFLOP/sec;
- CPU 性能利用率为 60%。
12. RI-RCCSD 二次激发 rhs2:PPL
- 程序函数:
get_riccsd_rhs2_o2v4 - 该项 (particle-particle ladder) 的渐进复杂度是
12.1 公式
PPL 贡献项满足 对称性。
12.2 最简程序实现
PPL 项的公式只有三项,且第 1、3 项都可以写为普通的矩阵乘法。如果不考虑效率与内存管理,这里的程序可以很方便地在 10 行以内复现出来。
#![allow(unused)] fn main() { // minimal lines of code of PPL term, but low efficiency and memory usage let scr_acbd = (b_vv - m1_vv).reshape((-1, naux)) % (b_vv - m1_vv).reshape((-1, naux)).t() - m1_vv.reshape((-1, naux)) % m1_vv.reshape((-1, naux)).t(); let scr_abcd = scr_acbd.into_shape((nvir, nvir, nvir, nvir)).into_swapaxes(1, 2); let tau2 = &t2 + t1.i((.., None, .., None)) * t1.i((None, .., None, ..)); rhs2 += 0.5 * (tau2.reshape((nocc * nocc, -1)) % scr_abcd.reshape((nvir * nvir, -1)).t()).into_shape(t2.shape()); }
这样的程序非常直观,但在实现更加高效与实用的程序时,我们必须考虑到
scr_acbd是 的临时张量,这个大小无论如何我们都无法接受,必须要分批计算;- PPL 贡献项在 具有二重对称性,其计算也可以利用二重对称性减少一半。
为了尽可能满足这两个需求,并且考虑到 PPL 项庞大的计算量,我们还对其性能有较高的要求。PPL 项的程序会是整个 RI-RCCSD 程序中最为繁杂、使用技巧最多的程序。
12.3 程序及其性能考量
12.3.1 指标 的分批
#![allow(unused)] fn main() { // batch initialization let nbatch_a = 8; let nbatch_b = 32; let mut batched_slices = vec![]; for a_start in (0..nvir).step_by(nbatch_a) { let a_end = (a_start + nbatch_a).min(nvir); for b_start in (0..a_end).step_by(nbatch_b) { let b_end = (b_start + nbatch_b).min(a_end); batched_slices.push(([a_start, a_end], [b_start, b_end])); } } batched_slices.into_par_iter().for_each(|([a_start, a_end], [b_start, b_end])| { let nbatch_a = a_end - a_start; let nbatch_b = b_end - b_start; // remaining of the PPL term program }); }
首先,我们对整个程序的规划是,我们只实现 的部分,而剩余的部分通过对称性补足。令
那么更新 时,策略则是
但是如果真的对每一对 作嵌套循环,那么在计算 时,就变成了矩阵-向量乘法问题:这是指在特定的 指标下, 问题在程序上会看作是 的向量与 矩阵的乘法。矩阵-向量乘法性能上总是不如矩阵乘法的,因此我们还必须避免简单的嵌套循环。
如何避免简单的嵌套循环,同时保证 的计算过程仍然有矩阵乘法的效率?我们的一种尝试是将计算作分批处理:其中指标 以步长 8 分批,指标 以步长 32 分批。这样的话,在计算 ,每一批次是 的矩阵与 矩阵;这通常就具有正常矩阵乘法的效率了。
其中,
- 指标 步长
nbatch_b的 32 是考虑到最后 的增量加和过程中,指标 对应了最连续的维度;在 elementwise 运算中,连续的维度越长越好。但这个数值最好不要太大,往下会看到, 的步长如果太大会造成更多的计算浪费、或者多线程任务分配不平衡。 - 指标 的步长
nbatch_a的 8 的选取,一来是依据 256 的矩阵乘法维度而定,而来是与 步长nbatch_b的 32 有 4 倍左右的差距,比较好地平衡了多线程任务分配与较少的计算浪费。
如此分批还是导致少许的性能损失,这是指在 的对角线附近,我们会引入一些多余的计算。但是如果体系比较大,这些性能损失都是可以接受的了。下图是对 分批计算的示意图:
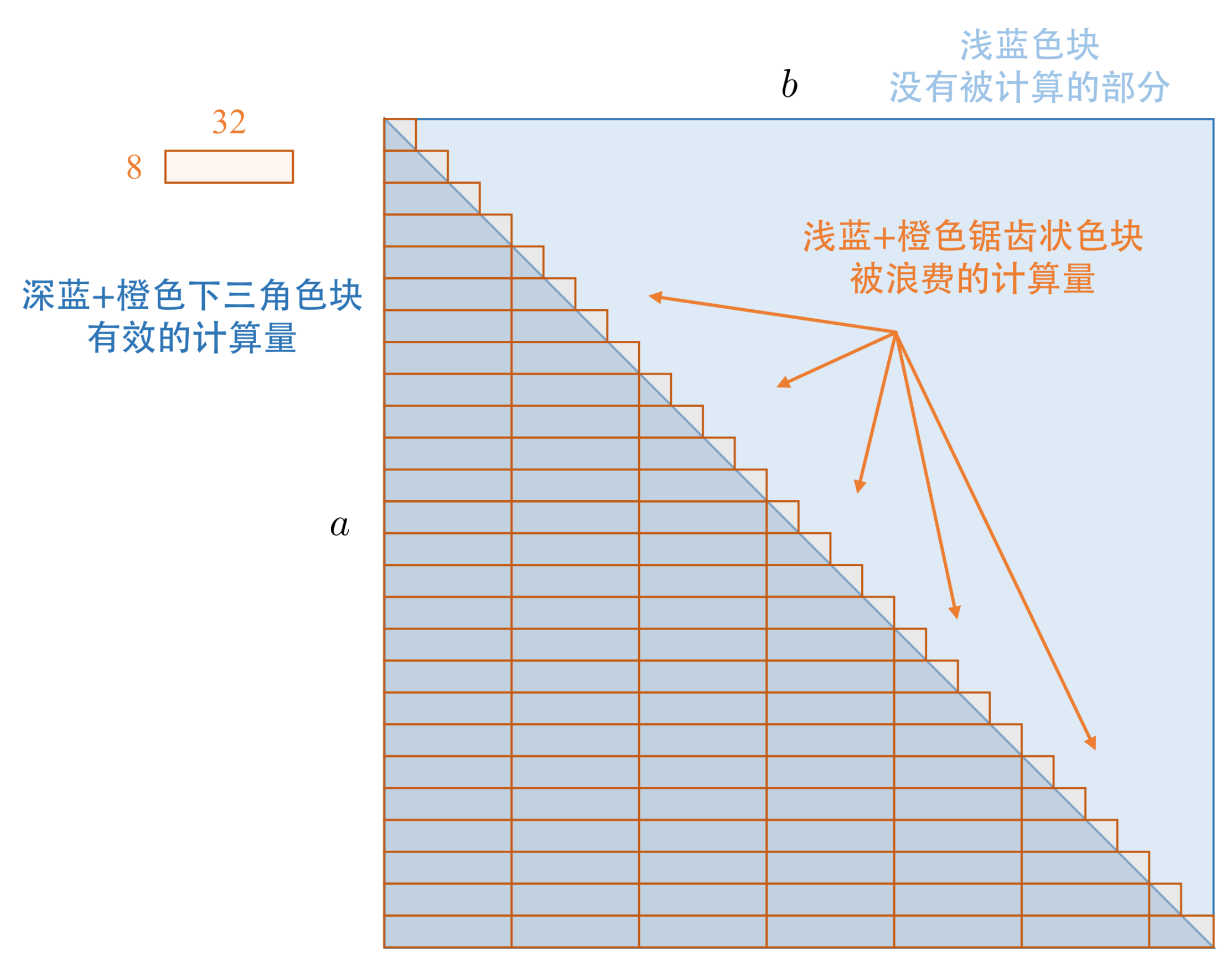
12.3.2 计算
#![allow(unused)] fn main() { // in batched (a, b) parallel iter // generate Wvvvv in batch (a, b) let mut scr_abcd: Tsr = rt::zeros(([nbatch_a, nbatch_b, nvir, nvir], &device)); for a in 0..nbatch_a { let a_shift = a + a_start; let scr_a_cP = b_vv.i(a_shift) - m1_vv.i(a_shift); for b in 0..nbatch_b { let b_shift = b + b_start; let scr_b_dP = b_vv.i(b_shift) - m1_vv.i(b_shift); scr_abcd.i_mut((a, b)).matmul_from(&scr_a_cP, &scr_b_dP.t(), 1.0, 1.0); scr_abcd.i_mut((a, b)).matmul_from(&m1_vv.i(a_shift), &m1_vv.i(b_shift).t(), -1.0, 1.0); } } }
这里的程序是比较标准的计算过程。需要留意的是
-
这里的程序实现的是分批次的 ,而不是完整的 。变量
scr_abcd是线程内部变量,不需要与其他线程作交互,只在对应的分批下有意义。 -
变量
a,b是从分批起点以 0 开始计数。如果要获得真正的虚轨道指标,需要加上分批起点a_start,b_start得到a_shift与b_shift。 -
这里原则上对被迭代变量
a,b使用嵌套循环并行也是可行的;但在实际的效率测评上,似乎这里对嵌套循环作并行会带来性能损失。
12.3.3 的计算
#![allow(unused)] fn main() { // in batched (a, b) parallel iter // t2 contribution from tau2 let mut scr_ijab: Tsr = unsafe { rt::empty(([nocc * nocc, nbatch_a * nbatch_b], &device)) }; scr_ijab.matmul_from( &t2.reshape((nocc * nocc, -1)), &scr_abcd.reshape((nbatch_a * nbatch_b, -1)).t(), 0.5, 0.0, ); // t1 contribution from tau2 let mut scr_ijab = scr_ijab.into_shape((nocc, nocc, nbatch_a, nbatch_b)).into_dim::<Ix4>(); for a in 0..nbatch_a { for b in 0..nbatch_b { *&mut scr_ijab.i_mut((.., .., a, b)) += 0.5 * &t1 % scr_abcd.i((a, b)) % t1.t(); } } }
与 HHL 项一样,本来应该是 与 作缩并;但为节省一些内存空间,我们打算分开计算 与 的缩并贡献。这会带来少许的计算量上升,但这些计算量相比于 PPL 项总耗时是非常少的。
12.3.4 对 作更新
#![allow(unused)] fn main() { // in batched (a, b) parallel iter // increment rhs2 from scr_ijab with symmetry let mut rhs2 = unsafe { rhs2.force_mut() }; for i in 0..nocc { for j in 0..nocc { for a in 0..nbatch_a { let a_shift = a + a_start; for b in 0..nbatch_b { let b_shift = b + b_start; if a_shift > b_shift { let scr_val = scr_ijab[[i, j, a, b]]; rhs2[[i, j, a_shift, b_shift]] += scr_val; rhs2[[j, i, b_shift, a_shift]] += scr_val; } else if a_shift == b_shift { rhs2[[i, j, a_shift, b_shift]] += scr_ijab[[i, j, a, b]]; } } } } } }
这一步是朴实无华的 for 循环赋值。好像没有更好的办法了。
不过这里有一个性能上需要留意的地方。
- RSTSR 的指标索引 (通过方括号 operator
[]) 是安全的,它会充分检查维度边界,确认索引的正确性。但这种维度检查实际上会严重影响程序效率。如果我们能确保指标不可能越界,可以对张量作 unsafe 的index_uncheck或index_mut_uncheck索引以避免冗余的维度检查。 - 高维度张量索引的代价总是比低维度张量要大。因此,如果在嵌套循环的某个阶段可以将问题转化为低维度张量,就可以取出子张量的视窗,在内层循环中索引低维度的子张量。
- 动态维度张量索引的代价总是比固定维度张量要大。如果张量索引这一步是性能瓶颈,那么最好通过
into_dim把张量转到确定的维度上。
综合这三点,更新后的赋值代码会是
#![allow(unused)] fn main() { // in batched (a, b) parallel iter // increment rhs2 from scr_ijab with symmetry for i in 0..nocc { for j in 0..nocc { let rhs2_ij = rhs2.i((i, j)).into_dim::<Ix2>(); let rhs2_ji = rhs2.i((j, i)).into_dim::<Ix2>(); let mut rhs2_ij = unsafe { rhs2_ij.force_mut() }; let mut rhs2_ji = unsafe { rhs2_ji.force_mut() }; let scr_ij = scr_ijab.i((i, j)).into_dim::<Ix2>(); for a in 0..nbatch_a { let a_shift = a + a_start; for b in 0..nbatch_b { let b_shift = b + b_start; unsafe { if a_shift > b_shift { let scr_val = scr_ij.index_uncheck([a, b]); *rhs2_ij.index_mut_uncheck([a_shift, b_shift]) += scr_val; *rhs2_ji.index_mut_uncheck([b_shift, a_shift]) += scr_val; } else if a_shift == b_shift { *rhs2_ij.index_mut_uncheck([a_shift, b_shift]) += scr_ij.index_uncheck([a, b]); } } } } } } }
不过,CCSD 的 的更新步骤,其 elementwise 操作数量是 的;相比于整体计算量 而言并不是很大。即使 elementwise 操作的性能较低,其影响并不显著。这与 CCSD(T) 的微扰项计算不同:CCSD(T) 中涉及到 的索引访问次数是 ,必须使用 index_uncheck 绕过边界检查以保证效率。
12.4 性能评价
| 计算类型 | 计算过程 | FLOPs 解析式 | FLOPs 实际数值 | 可能的提升空间 |
|---|---|---|---|---|
| 两次 | 1.99 TFLOPs | |||
| 0.07 TFLOPs | 内存换计算量 | |||
| 2.96 TFLOPs | ||||
| 总计 | 5.02 TFLOPs |
- 计算耗时约 10.5 sec,实际运行效率为 0.48 TFLOP/sec;
- CPU 性能利用率为 43%。
- 如前面讨论指标 的分批看到的,我们实际上多计算了少许的、对角线附近但在上三角区片的 情形。对于 、
nbatch_a = 8的情形,这个浪费的比例在 4% 左右;这对性能利用率有大约 2%-3% 的影响。 - 需要留意,从浮点计算量上来看,对于 RI-RCCSD 方法,PPL 项的 FLOPs 实际上比 PHL 项还要少一些。不过这个情况因基组而异;这里的基组是较小的 cc-pVDZ。对于较大的基组,PPL 项的 FLOPs 应该会比 PHL 项更多。
13. RI-RCCSD 其他计算过程与总结
在得到 rhs1 与 rhs2 后,我们就可以更新 CCSD 激发张量 t1 与 t2 (程序 get_amplitude_from_rhs):
为了更快地收敛 CCSD 激发张量,我们希望使用 DIIS 外推技术 (程序 diis_concate_amplitude、diis_obj.update、diis_split_amplitude)。在当前程序中,我们使用比较耗费内存的迭代方案;在实际工程中,还可以使用硬盘存储用于外推的张量。
在更新得到 CCSD 激发张量 t1 与 t2 后,我们或许希望得到 CCSD 能量,以确认计算结果是否收敛。但既然我们都要计算 CCSD 能量了,那么不可避免地需要得到第一部分的中间量 (程序 get_riccsd_intermediates_1)。出于这个特性,我们在 CCSD 张量更新程序 update_riccsd_amplitude 以及控制外部循环的主程序 riccsd_iteration 中,循环并非是从输入 t1 与 t2 开始的,而是从第二部分中间量开始:
- 初始化 Cholesky 分解积分 (
get_riccsd_intermediates_cderi) - 通过 MP2 方法获得
t1与t2初猜 (get_riccsd_initial_guess) - 第一次获得第一部分中间量 (
get_riccsd_intermediates_1) - 开始迭代循环
- 第二部分中间量 (
get_riccsd_intermediates_2) - 更新
rhs1与rhs2; - 更新
t1与t2(get_amplitude_from_rhs); - DIIS 外推;
- 第一部分中间量 (
get_riccsd_intermediates_1) - CCSD 能量 (
get_riccsd_energy) - 判断是否达到收敛标准
- 第二部分中间量 (
一次 CCSD 迭代过程中,
- 总计所有计算量不低于 13.0 TFLOPs;
- 计算耗时约 24.0 sec,实际运行效率不低于 0.54 TFLOP/sec;
- CPU 性能利用率不低于 49%。
-
考虑到 einsum 对程序快速实现的重要性,RSTSR 未来将会实现 einsum。 ↩
-
即使能使用 einsum 作缩并,张量的指标排布顺序对于程序运行效率的提升仍然是重要的。可以直接划归为矩阵乘法的 einsum 才能达到最高的效率,其他情形的 einsum 一般都会对性能有一定程度的损失。 ↩
-
感兴趣的读者可以参考下述程序的实现文献:Q-Chem, Psi4 fnocc, FHI-Aims, Gamess US。 ↩
RI-RCCSD(T):极简到高效率
实现内容:RI-RCCSD(T) (CCSD with triplet perturbation correction)
- 程序:
ri_rccsdt_naive.rs(gitee, github) - 最简实现,无视性能
- 该程序总共约 60 行 (其中调用的函数
prepare_intermediates复用了程序ri_rccsdt_slow.rs的实现)
- 程序:
ri_rccsdt_slow.rs(gitee, github) - 与高性能的 RI-RCCSD(T) 具有相同的算法实现与程序结构,但没有引入一些关键的程序技巧
- 该程序总共约 150 行,其中多个程序复用的函数
prepare_intermediates约 60 行
- 程序:
ri_rccsdt.rs(gitee, github) - 性能较高
- 体系 (H2O)10 cc-pVDZ (, ,无冻结轨道)
- 计算设备 Ryzen HX7945,16 cores,算力约 1.1 TFLOP/sec
- CCSD(T) 的三次微扰部分耗时约 1010 sec,CPU 性能利用率不低于 34%,可能还有提升空间
- 本文档的所有性能分析均基于 OpenBLAS 后端讨论
- 该程序总共约 150 行 (其中调用的函数
prepare_intermediates复用了程序ri_rccsdt_slow.rs的实现) - 本程序的算法参考了 PySCF 在 CCSD(T) 上的实现
目录
1. RI-RCCSD(T) 实现前言
CCSD(T) 方法是通过微扰的方法,在仅有基于 CCSD 得到的 的一次、二次激发振幅基础上,给出三次激发的能量。微扰的三次激发能量的定义并不唯一,CCSD(T) 仅仅是多种三次微扰方法的其中一种;由于其具有较好的计算量与计算精度平衡,因此作为小分子计算化学方法广为接受与使用,常被称为“黄金标准”。至于这个“黄金”是否名不副实,或者是否是一种 overkill,这因具体的计算化学问题而异。
我们在此不讨论 CCSD(T) 的理论本身。
尽管我们将实现的是闭壳层 CCSD(T) 在 RI 下的近似,但若没有进一步近似,那么 RI 近似本身并不会真的节省 CCSD(T) 的计算量。因此,下述程序的实现,基本上与普通的 CCSD(T) 一致。内存上,我们要求非常大的 大小的张量;这会比 CCSD 单次迭代的内存量要大得多 (如果不考虑到 incore DIIS 对内存的额外消耗)。
2. RCCSD(T) 中间量
对于 CCSD(T) 的程序实现,我们需要一些中间张量。这部分的计算相对于 CCSD(T) 本身并不大,因此就在这里作讨论。
2.1 记号与公式
从公式上,CCSD(T) 涉及到 6-D 张量的计算,其指标是 ,即 3 个非占轨道与 3 个占据轨道。在迭代时,我们的主基调是对非占轨道 优先迭代1;因此会希望程序用到的张量中,非占轨道往尽量放在最不连续的维度上 (row-major 下是靠前的维度),占据轨道尽量放在最连续的维度上靠 (col-major 下是靠后的维度)。
为此,我们在使用分子轨道下的双电子积分、以及激发张量时,其维度顺序都与 CCSD 时稍有不同。仅针对 CCSD(T) 的实现,定义
需要留意,上式中的 的转置顺序与 和 不同。其中最大的张量是 的 浮点数的 4-D 张量。
2.2 程序
这里的程序都是比较标准的做法。
#![allow(unused)] fn main() { // ri_rccsdt_slow.rs, in fn `prepare_intermediates` let t1_t = t1.t().into_contig(RowMajor); let t2_t = t2.transpose((2, 3, 1, 0)).into_contig(RowMajor); let d_ooo = eo.i((.., None, None)) + eo.i((None, .., None)) + eo.i((None, None, ..)); let eri_vvov_t = unsafe { rt::empty(([nvir, nvir, nocc, nvir], &device)) }; (0..nvir).into_par_iter().for_each(|a| { (0..nvir).into_par_iter().for_each(|c| { let mut eri_vvov_t = unsafe { eri_vvov_t.force_mut() }; eri_vvov_t.i_mut([a, c]).matmul_from(&b_ov.i((.., a)), &b_vv.i((.., c)).t(), 1.0, 0.0); }); }); let eri_vooo_t = unsafe { rt::empty(([nvir, nocc, nocc, nocc], &device)) }; (0..nvir).into_par_iter().for_each(|a| { (0..nocc).into_par_iter().for_each(|l| { let mut eri_vooo_t = unsafe { eri_vooo_t.force_mut() }; eri_vooo_t.i_mut([a, l]).matmul_from(&b_oo.i(l), &b_ov.i((.., a)).t(), 1.0, 0.0); }); }); let eri_vvoo_t = unsafe { rt::empty(([nvir, nvir, nocc, nocc], &device)) }; (0..nvir).into_par_iter().for_each(|a| { (0..nvir).into_par_iter().for_each(|b| { let mut eri_vvoo_t = unsafe { eri_vvoo_t.force_mut() }; eri_vvoo_t.i_mut([a, b]).matmul_from(&b_ov.i((.., a)), &b_ov.i((.., b)).t(), 1.0, 0.0); }); }); }
2.3 性能评价
| 计算变量 | FLOPs 解析式 | FLOPs 实际数值 |
|---|---|---|
| 0.52 TFLOPs | ||
| 0.04 TFLOPs | ||
| 0.14 TFLOPs | ||
| 总计 | 0.70 TFLOPs |
- 计算耗时约 1.4 sec,实际运行效率为 0.50 TFLOP/sec;
- CPU 性能利用率为 45%;
- 在 CCSD(T) 计算中,这部分 计算量相对而言是可以忽略不计的。
3. RI-RCCSD(T) 最简实现
RI-RCCSD(T) 的公式尽管不算最少 (相比于 MP2 方法),但也相比于 RI-RCCSD 要少许多了。其表达式的复杂性与 Hartree-Fock 相当。因此,我们可以用较少的代码实现。
我们可以参考 Shen JCTC 2019 公式 (10) 附近的表达式,不过在约定俗成上有所区别:
上述 6-D 张量,以 为例,在程序中其张量对应的指标顺序是 。
上式中,计算 与 使用到转置后的分子轨道下电子积分与 CCSD 激发张量;因此为了与程序作对照,我们需要将公式改写为
的计算过程中,在指标 下作外循环,其索引得到的子张量都是连续的;并且可以通过维度更改 (reshape),不需要复制到新的张量,就可以通过矩阵乘法给出结果。这解释了我们为何要如此设计 CCSD 激发张量与分子轨道下双电子积分的指标顺序的原因。
RCCSD(T) 最简程序实现代码如下,核心代码总共 25 行:
#![allow(unused)] fn main() { // ri_rccsdt_naive.rs let wp: Tsr = unsafe { rt::empty(([nvir, nvir, nvir, nocc, nocc, nocc], &device)) }; (0..nvir).into_par_iter().for_each(|a| { (0..nvir).into_par_iter().for_each(|b| { (0..nvir).into_par_iter().for_each(|c| unsafe { let mut wp = wp.force_mut(); let wp_1 = eri_vvov_t.i((a, b)) % t2_t.i(c).reshape((nvir, -1)); let wp_2 = t2_t.i((a, b)).t() % eri_vooo_t.i(c).reshape((nocc, -1)); wp.i_mut([a, b, c]).assign(wp_1.reshape((nocc, nocc, nocc)) - wp_2.reshape((nocc, nocc, nocc))); }); }); }); let w = wp.transpose((0, 1, 2, 3, 4, 5)) + wp.transpose((0, 2, 1, 3, 5, 4)) + wp.transpose((1, 0, 2, 4, 3, 5)) + wp.transpose((1, 2, 0, 4, 5, 3)) + wp.transpose((2, 0, 1, 5, 3, 4)) + wp.transpose((2, 1, 0, 5, 4, 3)); let v = &w + t1_t.i((.., None, None, .., None, None)) * eri_vvoo_t.i((None, .., .., None, .., ..)) + t1_t.i((None, .., None, None, .., None)) * eri_vvoo_t.i((.., None, .., .., None, ..)) + t1_t.i((None, None, .., None, None, ..)) * eri_vvoo_t.i((.., .., None, .., .., None)); let (so, sv) = (slice!(0, nocc), slice!(nocc, nmo)); let d = -mo_energy.i((sv, None, None, None, None, None)) - mo_energy.i((None, sv, None, None, None, None)) - mo_energy.i((None, None, sv, None, None, None)) + mo_energy.i((None, None, None, so, None, None)) + mo_energy.i((None, None, None, None, so, None)) + mo_energy.i((None, None, None, None, None, so)); let z: Tsr = 4 * &w + w.transpose((0, 1, 2, 4, 5, 3)) + w.transpose((0, 1, 2, 5, 3, 4)) - 2 * w.transpose((0, 1, 2, 5, 4, 3)) - 2 * w.transpose((0, 1, 2, 3, 5, 4)) - 2 * w.transpose((0, 1, 2, 4, 3, 5)); let e_corr_pt = (z * v / &d).sum() / 3.0; }
但显然,这样的代码距离能用还有不少问题:
-
内存用量庞大。这是最主要的问题。该程序需要引入多个 大小的张量;对于 (H2O)4 cc-pVDZ 基组,一个这样的张量就要 26 GB;对于 (H2O)5 甚至要 100 GB。这显然是不能接受的。
-
Elementwise 操作的优化不足。上述程序还用到了很多的 broadcast 与 transpose;这些 elementwise 运算会占用 的内存带宽。单个内存中 elementwise 操作的时间代价通常比矩阵乘法中单步的乘加融合 (FMA) 代价要更大。考虑到 CCSD(T) 的主要计算量是 即较小的 的矩阵乘法 FLOPs,内存带宽占用只少一个数量级,因此 CCSD(T) 的 elementwise 操作最好有较高效率的实现。
- 这与 CCSD 的情形不同。CCSD 是较大的 的矩阵乘法 FLOPs,与 的 elementwise 操作。因此,CCSD 的实现一般只需要注重矩阵乘法本身的实现即可。
4. RI-RCCSD(T) 初步实现
4.1 固定外循环指标的 实现
作为初步实现,我们首先要解决内存用量庞大的问题。
作为解决方法,我们对指标 作并行的外循环,使得循环内部最大的张量只有 3-D 的大小,如 、、 等等。
为此,我们将计算 的部分单独拉出来成为一个函数:
#![allow(unused)] fn main() { // ri_rccsdt_slow.rs fn get_w(abc: [usize; 3], intermediates: &RCCSDTIntermediates) -> Tsr { let t2_t = intermediates.t2_t.as_ref().unwrap(); let eri_vvov_t = intermediates.eri_vvov_t.as_ref().unwrap(); let eri_vooo_t = intermediates.eri_vooo_t.as_ref().unwrap(); let nvir = t2_t.shape()[0]; let nocc = t2_t.shape()[2]; let [a, b, c] = abc; let mut w = eri_vvov_t.i([a, b]) % t2_t.i(c).reshape([nvir, nocc * nocc]); w.matmul_from(&t2_t.i([a, b]).t(), &eri_vooo_t.i(c).reshape([nocc, nocc * nocc]), -1.0, 1.0); w.into_shape([nocc, nocc, nocc]) } }
4.2 处理 的置换求和
我们注意到 是经过置换求和后得到的结果:
这意味着,指标 下的结果 依赖于其他指标 。
为了破除这种依赖关系,使得外循环指标 内的任务相互独立,我们的做法是
- 只对 上超三角部分作迭代 (迭代次数是 或约 次)。
- 在循环内部现场生成置换的 、 等张量,即对外循环中特定的 指标,我们会生成 6 次 的张量。
#![allow(unused)] fn main() { // ri_rccsdt_slow.rs fn ccsd_t_energy_contribution(abc: [usize; 3], mol_info: &RCCSDInfo, intermediates: &RCCSDTIntermediates) -> f64 { // ... // let [a, b, c] = abc; let w = get_w([a, b, c], intermediates) + get_w([a, c, b], intermediates).transpose([0, 2, 1]) + get_w([b, c, a], intermediates).transpose([2, 0, 1]) + get_w([b, a, c], intermediates).transpose([1, 0, 2]) + get_w([c, a, b], intermediates).transpose([1, 2, 0]) + get_w([c, b, a], intermediates).transpose([2, 1, 0]); // ... // } }
4.3 其余的计算
其余部分的张量计算就没有非常特别的部分了。
但在能量求和时,需要注意到,我们使用了上超三角的 的迭代,每个被迭代到的指标 的权重并不相同。
其中,权重 的数值取决于它在哪个对角线上:
#![allow(unused)] fn main() { // ri_rccsdt_slow.rs fn ccsd_t_energy_contribution(abc: [usize; 3], mol_info: &RCCSDInfo, intermediates: &RCCSDTIntermediates) -> f64 { // ... // let v = &w + t1_t.i((a, .., None, None)) * eri_vvoo_t.i([b, c]).i((None, .., ..)) + t1_t.i((b, None, .., None)) * eri_vvoo_t.i([a, c]).i((.., None, ..)) + t1_t.i((c, None, None, ..)) * eri_vvoo_t.i([a, b]).i((.., .., None)); let d = -(ev[[a]] + ev[[b]] + ev[[c]]) + d_ooo; let z = 4.0 * &w + w.transpose([1, 2, 0]) + w.transpose([2, 0, 1]) - 2.0 * w.transpose([2, 1, 0]) - 2.0 * w.transpose([0, 2, 1]) - 2.0 * w.transpose([1, 0, 2]); let e_tsr: Tsr = (z * v) / d; let fac = if a == c { 1.0 / 3.0 } else if a == b || b == c { 1.0 } else { 2.0 }; fac * e_tsr.sum() } }
4.4 性能评价
| 计算表达式 | FLOPs 解析式 | FLOPs 实际数值 |
|---|---|---|
| 296 TFLOPs | ||
| 78 TFLOPs | ||
| 总计 | 374 TFLOPs |
- 这里我们没有统计其他 的计算步骤;
- 计算耗时约 1603 sec,实际运行效率不低于 0.23 TFLOP/sec;
- CPU 性能利用率不低于 21%。
5. RI-RCCSD(T) 高性能实现
5.1 效率改进方案与实现
上述程序的程序性能主要受制于下面几个因素:
- 低效的张量索引;
- 较为低效的 elementwise 运算;
- 过分频繁的内存分配;
作为解决方案,
A. 整个程序经常处理张量转置;注意到每次循环时,张量的转置顺序都是固定的,那么可以在外循环前先将转置顺序储存为数组,以避免每次循环内再对转置的位置作计算。
#![allow(unused)] fn main() { // ri_rccsdt.rs pub struct TransposedIndices { pub tr_012: Vec<usize>, pub tr_021: Vec<usize>, pub tr_102: Vec<usize>, pub tr_120: Vec<usize>, pub tr_201: Vec<usize>, pub tr_210: Vec<usize>, } fn prepare_transposed_indices(nocc: usize) -> TransposedIndices { let device = DeviceTsr::default(); let base = rt::arange((nocc * nocc * nocc, &device)).into_shape([nocc, nocc, nocc]); let tr_012 = base.transpose([0, 1, 2]).reshape(-1).to_vec(); let tr_021 = base.transpose([0, 2, 1]).reshape(-1).to_vec(); let tr_102 = base.transpose([1, 0, 2]).reshape(-1).to_vec(); let tr_120 = base.transpose([1, 2, 0]).reshape(-1).to_vec(); let tr_201 = base.transpose([2, 0, 1]).reshape(-1).to_vec(); let tr_210 = base.transpose([2, 1, 0]).reshape(-1).to_vec(); TransposedIndices { tr_012, tr_021, tr_102, tr_120, tr_201, tr_210 } } }
B. 为了避免频繁的内存分配,在计算 时,应在调用函数 get_w 时重复使用先前的内存 buffer,输出张量应尽量避免新分配内存。下述代码也引入了 tr_indices,这就是上面提到的预先存储好的转置顺序。
#![allow(unused)] fn main() { // ri_rccsdt.rs fn get_w(abc: [usize; 3], mut w: TsrMut, mut wbuf: TsrMut, intermediates: &RCCSDTIntermediates, tr_indices: &[usize]) { let t2_t = intermediates.t2_t.as_ref().unwrap(); let eri_vvov_t = intermediates.eri_vvov_t.as_ref().unwrap(); let eri_vooo_t = intermediates.eri_vooo_t.as_ref().unwrap(); let device = t2_t.device().clone(); let nvir = t2_t.shape()[0]; let nocc = t2_t.shape()[2]; let [a, b, c] = abc; // hack for TsrMut to reshape to nocc, nocc * nocc let mut wbuf = rt::asarray((wbuf.raw_mut(), [nocc, nocc * nocc].c(), &device)); wbuf.matmul_from(&eri_vvov_t.i([a, b]), &t2_t.i(c).reshape([nvir, nocc * nocc]), 1.0, 0.0); wbuf.matmul_from(&t2_t.i([a, b]).t(), &eri_vooo_t.i(c).reshape([nocc, nocc * nocc]), -1.0, 1.0); // add to w with transposed indices let w_raw = w.raw_mut(); let wbuf_raw = wbuf.raw(); w_raw.iter_mut().zip(tr_indices).for_each(|(w_elem, &tr_idx)| { *w_elem += wbuf_raw[tr_idx]; }); } }
#![allow(unused)] fn main() { // ri_rccsdt.rs, in fn `ccsd_t_energy_contribution` let mut w = rt::zeros(([nocc, nocc, nocc], &device)); let mut wbuf = unsafe { rt::empty(([nocc, nocc, nocc], &device)) }; get_w([a, b, c], w.view_mut(), wbuf.view_mut(), intermediates, &tr_indices.tr_012); get_w([a, c, b], w.view_mut(), wbuf.view_mut(), intermediates, &tr_indices.tr_021); get_w([b, c, a], w.view_mut(), wbuf.view_mut(), intermediates, &tr_indices.tr_201); get_w([b, a, c], w.view_mut(), wbuf.view_mut(), intermediates, &tr_indices.tr_102); get_w([c, a, b], w.view_mut(), wbuf.view_mut(), intermediates, &tr_indices.tr_120); get_w([c, b, a], w.view_mut(), wbuf.view_mut(), intermediates, &tr_indices.tr_210); }
C. 涉及到的 elementwise 运算中,计算 时使用到了 broadcast 数乘;但目前 RSTSR 的 broadcast elementwise 运算的实现效率仅仅满足一般需求,其性能没有达到极限。如果确实是 broadcast elementwise 导致性能低下,建议手动展开 for 循环。
D. 用于计算 的 broadcast elementwise 运算,若手动展开 for 循环,则需要对张量进行索引。为更高效地进行张量索引,一般需要做三件事:
- 在确保索引不会越界的情况下,使用
index_uncheck以避免越界检查 (这是决定性因素); - 低维度的索引代价总是小于高维度;尽可能先取出子张量,对更低维度的子张量进行索引;
- 若在索引前能确保张量维度的大小,则尽量通过
into_dim转换到静态维度。
E. 如果是多步计算,譬如计算 时涉及到多个张量的求和,对于这种情形最好使用迭代器以避免多次写入:对于特定的指标 多次读入张量并求和、但只写入一次到 2。
F. 实际上,当 计算完毕后,后面的计算中,内循环的指标 之间其实没有关联。这意味着不需要对张量 、、 作新的内存分配或存储;他们的数值随内循环 的迭代生成求得能量的贡献 (通过 fold 函数实现能量贡献的累加),就可以直接消亡。
#![allow(unused)] fn main() { // ri_rccsdt.rs, in fn `ccsd_t_energy_contribution` let eri_vvoo_t_ab = eri_vvoo_t.i([a, b]).into_dim::<Ix2>(); let eri_vvoo_t_bc = eri_vvoo_t.i([b, c]).into_dim::<Ix2>(); let eri_vvoo_t_ca = eri_vvoo_t.i([c, a]).into_dim::<Ix2>(); let t1_t_a = t1_t.i(a).into_dim::<Ix1>(); let t1_t_b = t1_t.i(b).into_dim::<Ix1>(); let t1_t_c = t1_t.i(c).into_dim::<Ix1>(); let iter_ijk = (0..nocc).cartesian_product(0..nocc).cartesian_product(0..nocc); let d_abc = -(ev[[a]] + ev[[b]] + ev[[c]]); let w_raw = w.raw(); let e_sum = izip!( iter_ijk, w.raw().iter(), d_ooo.raw().iter(), tr_indices.tr_012.iter(), tr_indices.tr_120.iter(), tr_indices.tr_201.iter(), tr_indices.tr_210.iter(), tr_indices.tr_021.iter(), tr_indices.tr_102.iter() ) .fold(0.0, |acc, (((i, j), k), &w_val, &d_ijk, &tr_012, &tr_120, &tr_201, &tr_210, &tr_021, &tr_102)| unsafe { let v_val = w_val + t1_t_a.index_uncheck([i]) * eri_vvoo_t_bc.index_uncheck([j, k]) + t1_t_b.index_uncheck([j]) * eri_vvoo_t_ca.index_uncheck([k, i]) + t1_t_c.index_uncheck([k]) * eri_vvoo_t_ab.index_uncheck([i, j]); let z_val = 4.0 * w_raw[tr_012] + w_raw[tr_120] + w_raw[tr_201] - 2.0 * (w_raw[tr_210] + w_raw[tr_021] + w_raw[tr_102]); let d_val = d_abc + d_ijk; acc + z_val * v_val / d_val }); let fac = if a == c { 1.0 / 3.0 } else if a == b || b == c { 1.0 } else { 2.0 }; fac * e_sum }
5.2 性能评价
| 计算表达式 | FLOPs 解析式 | FLOPs 实际数值 |
|---|---|---|
| 296 TFLOPs | ||
| 78 TFLOPs | ||
| 总计 | 374 TFLOPs |
- 这里我们没有统计其他 的计算步骤;
- 计算耗时约 1003 sec,实际运行效率不低于 0.37 TFLOP/sec;
- CPU 性能利用率不低于 34%。
-
这里我们对非占轨道 作外循环优先迭代,而不是对占据轨道 优先迭代。
在实现对占据轨道 作外循环、非占轨道 作内循环的程序后,对于当前关心的体系 (5-10 个水分子),程序效率会有显著下降。我们认为这比较可能是因为循环中,生成的 大小的张量会频繁读写、占用了较多的内存带宽,且其大小显著大于 L3 缓存、带宽效率也较低。同时,其计算过程中涉及到一步 与 得到 的矩阵乘法,即两个较小的矩阵相乘得到更大的矩阵;这类矩阵乘法不太容易达到理想浮点效率。
相对地,对非占轨道 作外循环时,中间张量是 浮点数大小;对于 (H2O)10 体系,这也只有 2 MB。在单个线程内部,较小的张量的 elementwise 操作与矩阵乘法,其缓存命中率较高,容易达到更高的计算效率。 ↩
-
这也是 RSTSR 目前不擅长的部分,即它不支持延迟计算 (lazy evaluation)。不引入延迟计算,既是出于使用者方便的角度,也可以减少 RSTSR 开发者维护的难度。对于 C++ 中支持延迟计算的库,可以参考 Eigen。RSTSR 的张量支持各种迭代器 (依元素迭代或依特定维度迭代),并支持并行迭代。利用这些迭代器,也可以提升计算效率,避免多次写入;当然,这里高性能的 RI-RCCSD(T) 的实现是依预先存储的指针位置进行迭代,这个实现策略的性能更高但技巧性太强。 ↩